消息队列-kafka
1、应用场景
1.1 kafka场景
Kafka最初是由LinkedIn公司采用Scala语言开发,基于ZooKeeper,现在已经捐献给了Apache基金会。目前Kafka已经定位为一个分布式流式处理平台,它以 高吞吐、可持久化、可水平扩展、支持流处理等多种特性而被广泛应用。
Apache Kafka能够支撑海量数据的数据传递。在离线和实时的消息处理业务系统中,Kafka都有广泛的应用。
(1)日志收集:收集各种服务的log,通过kafka以统一接口服务的方式开放 给各种consumer,例如Hadoop、Hbase、Solr等;
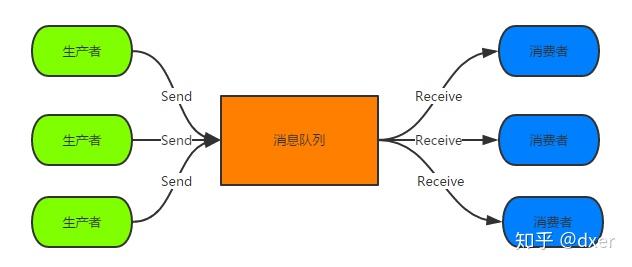
(2)消息系统:解耦和生产者和消费者、缓存消息等;
(3)用户活动跟踪:Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点 击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时 的监控分析,或者装载到Hadoop、数据仓库中做离线分析和挖掘;
(4)运营指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作 的集中反馈,比如报警和报告;
(5)流式处理:比如spark streaming和storm;
1.2 kafka特性
kafka以高吞吐量著称,主要有以下特性:
(1)高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒;
(2)可扩展性:kafka集群支持热扩展;
(3)持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失;
(4)容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败);
(5)高并发:支持数千个客户端同时读写;
1.3 消息对比
- 如果普通的业务消息解耦,消息传输,rabbitMq是首选,它足够简单,管理方便,性能够用。
- 如果在上述,日志、消息收集、访问记录等高吞吐,实时性场景下,推荐kafka,它基于分布式,扩容便捷
- 如果很重的业务,要做到极高的可靠性,考虑rocketMq,但是它太重。需要你有足够的了解
1.4 大厂应用
- 京东通过kafka搭建数据平台,用于用户购买、浏览等行为的分析。成功抗住6.18的流量洪峰
- 阿里借鉴kafka的理念,推出自己的rocketmq。在设计上参考了kafka的架构体系
2、基础组件
2.1 角色

- broker:节点,就是你看到的机器
- provider:生产者,发消息的
- consumer:消费者,读消息的
- zookeeper:信息中心,记录kafka的各种信息的地方
- controller:其中的一个broker,作为leader身份来负责管理整个集群。如果挂掉,借助zk重新选主
2.2 逻辑组件

- topic:主题,一个消息的通道,收发总得知道消息往哪投
- partition:分区,每个主题可以有多个分区分担数据的传递,多条路并行,吞吐量大
- Replicas:副本,每个分区可以设置多个副本,副本之间数据一致。相当于备份,有备胎更可靠
- leader & follower:主从,上面的这些副本里有1个身份为leader,其他的为follower。leader处理partition的所有读写请求
2.3 副本集合
- AR:所有副本的统称,AR=ISR+OSR
- ISR:同步中的副本,可以参与leader选主。一旦落后太多(数量滞后和时间滞后两个维度)会被踢到OSR。
- OSR:踢出同步的副本,一直追赶leader,追上后会进入ISR
2.4 消息标记

- offset:偏移量,消息消费到哪一条了?每个消费者都有自己的偏移量
- HW:(high watermark):副本的高水印值,客户端最多能消费到的位置,HW值为8,代表offset为[0,8]的9条消息都可以被消费到,它们是对消费者可见的,而[9,12]这4条消息由于未提交,对消费者是不可见的。
- LEO:(log end offset):日志末端位移,代表日志文件中下一条待写入消息的offset,这个offset上实际是没有消息的。不管是leader副本还是follower副本,都有这个值。
那么这三者有什么关系呢?
比如在副本数等于3的情况下,消息发送到Leader A之后会更新LEO的值,Follower B和Follower C也会实时拉取Leader A中的消息来更新自己,HW就表示A、B、C三者同时达到的日志位移,也就是A、B、C三者中LEO最小的那个值。由于B、C拉取A消息之间延时问题,所以HW一般会小于LEO,即LEO>=HW。
具体的同步原理,下面章节会详细讲到
3.1 发展历程
http://kafka.apache.org/downloads

3.1.1 版本命名
Kafka在1.0.0版本前的命名规则是4位,比如0.8.2.1,0.8是大版本号,2是小版本号,1表示打过1个补丁
现在的版本号命名规则是3位,格式是“大版本号”+“小版本号”+“修订补丁数”,比如2.5.0,前面的2代表的是大版本号,中间的5代表的是小版本号,0表示没有打过补丁
我们所看到的下载包,前面是scala编译器的版本,后面才是真正的kafka版本。
3.1.2 演进历史
0.7版本
只提供了最基础的消息队列功能。
0.8版本
引入了副本机制,至此Kafka成为了一个真正意义上完备的分布式高可靠消息队列解决方案。
0.9版本
增加权限和认证,使用Java重写了新的consumer API,Kafka Connect功能;不建议使用consumer API;
0.10版本
引入Kafka Streams功能,正式升级成分布式流处理平台;建议版本0.10.2.2;建议使用新版consumer API
0.11版本
producer API幂等,事务API,消息格式重构;建议版本0.11.0.3;谨慎对待消息格式变化
1.0和2.0版本
Kafka Streams改进;建议版本2.0;
3.2 集群搭建(助学)
1)原生启动
kafka启动需要zookeeper,第一步启动zk:
1 | docker run --name zookeeper-1 -d -p 2181 zookeeper:3.4.13 |
原生安装:下载后解压启动即可 http://kafka.apache.org/downloads
1 | bin/kafka-server-start.sh config/server.properties |
2)推荐docker-compose 一键启动
1 | #参考资料中的kafka.yml |
3.3 组件探秘
命令行工具是管理kafka集群最直接的工具。官方自带,不需要额外安装。
3.2.1 主题创建
1 | 进入容器 |
3.2.2 查看主题
1 | kafka-topics.sh --zookeeper zookeeper:2181 --list |
3.2.3 主题详情
1 | kafka-topics.sh --zookeeper zookeeper:2181 --describe --topic test |
3.2.4 消息收发
1 | 使用docker连接任意集群中的一个容器 |
3.2.5 分组消费
1 | 启动两个consumer时,如果不指定group信息,消息被广播 |
注意!!!
这是在消费者和分区数相等(都是2)的情况下。
如果同一group下的 ( 消费者数量 > 分区数量 ) 那么就会有消费者闲置。
验证方式:
可以再多启动几个消费者试一试,会发现,超出2个的时候,有的始终不会消费到消息。
停掉可以消费到的,那么闲置的会被激活,进入工作状态
3.2.6 指定分区
1 | 指定分区通过参数 --partition,注意!需要去掉上面的group |
3.2.7 偏移量
1 | 偏移量决定了消息从哪开始消费,支持:开头,还是末尾 |
3.4 zk探秘
前面说过,zk存储了kafka集群的相关信息,本节来探索内部的秘密。
kafka的信息记录在zk中,进入zk容器,查看相关节点和信息
1 | docker exec -it kafka_zookeeper_1 sh |

3.4.1 broker信息
1 | [zk: localhost:2181(CONNECTED) 0] ls /brokers |
3.4.2 主题与分区
1 | 分区节点路径 |
3.4.3 消费者与偏移量
1 | [zk: localhost:2181(CONNECTED) 15] ls /consumers |
kafka 消费者记录 group 的消费 偏移量 有两种方式 :
1)kafka 自维护 (新)
2)zookpeer 维护 (旧) ,已经逐渐被废弃
查看方式:
上面的消费用的是控制台工具,这个工具使用–bootstrap-server,不经过zk,也就不会记录到/consumers下。
其消费者的offset会更新到一个kafka自带的topic【__consumer_offsets】下面
1 | 先起一个消费端,指定group |
当前与LEO保持一致,说明消息都完整的被消费过

停掉consumer后,往provider中再发几条记录,offset开始滞后:

重新启动consumer,消费到最新的消息,同时再返回看偏移量,消息得到同步:

3.4.4 controller
1 | 当前集群中的主控节点是谁 |
3.5 km
3.5.1 启动
kafka-manager是目前最受欢迎的kafka集群管理工具,最早由雅虎开源。提供可视化kafka集群操作
官网:https://github.com/yahoo/kafka-manager/releases
注意它的版本,docker社区的景象版本滞后于kafka,我们自己来打镜像。
1 | #Dockerfile |
3.5.2 使用
使用km可以方便的查看以下信息:
- cluster:创建集群,填写zk地址,选中jmx,consumer信息等选项
- brokers:列表,机器信息
- topic:主题信息,主题内的分区信息。创建新的主题,增加分区
- cosumers: 消费者信息,偏移量等
3.场景实例
Kafka 的应用场景
Kafka 作为一款热门的消息队列中间件,具备高效可靠的消息异步传递机制,主要用于不同系统间的数据交流和传递。下面给大家介绍一下 Kafka 在分布式系统中的 7 个常用应用场景。
- 日志处理与分析
- 推荐数据流
- 系统监控与报警
- CDC(数据变更捕获)
- 系统迁移
- 事件溯源
- 消息队列
1. 日志处理与分析
日志收集是 Kafka 最初的设计目标之一,也是最常见的应用场景之一。可以用 Kafka 收集各种服务的日志,如 web 服务器、服务器日志、数据库服务器等,通过 Kafka 以统一接口服务的方式开放给各种消费者,例如 Flink、Hadoop、Hbase、ElasticSearch 等。这样可以实现分布式系统中海量日志数据的处理与分析。
下图是一张典型的 ELK(Elastic-Logstash-Kibana)分布式日志采集架构。
- 购物车服务将日志数据写在 log 文件中。
- Logstash 读取日志文件发送到 Kafka 的日志主题中。
- ElasticSearch 订阅日志主题,建立日志索引,保存日志数据。
- 开发者通过 Kibana 连接到 ElasticSeach 即可查询其日志索引内容。

2. 推荐数据流
流式处理是 Kafka 在大数据领域的重要应用场景之一。可以用 Kafka 作为流式处理平台的数据源或数据输出,与 Spark Streaming、Storm、Flink 等框架进行集成,实现对实时数据的处理和分析,如过滤、转换、聚合、窗口、连接等。
淘宝、京东这样的线上商城网站会通过用户过去的一些行为(点击、浏览、购买等)来和相似的用户计算用户相似度,以此来给用户推荐可能感兴趣的商品。
下图展示了常见推荐系统的工作流程。
- 将用户的点击流数据发送到 Kafka 中。
- Flink 读取 Kafka 中的流数据实时写入数据湖中其进行聚合处理。
- 机器学习使用来自数据湖的聚合数据进行训练,算法工程师也会对推荐模型进行调整。
这样推荐系统就能够持续改进对每个用户的推荐相关性。

3. 系统监控与报警
Kafka 常用于传输监控指标数据。例如,大一点的分布式系统中有数百台服务器的 CPU 利用率、内存使用情况、磁盘使用率、流量使用等指标可以发布到 Kafka。然后,监控应用程序可以使用这些指标来进行实时可视化、警报和异常检测。
下图展示了常见监控报警系统的工作流程。
- 采集器(agent)读取购物车指标发送到 Kafka 中。
- Flink 读取 Kafka 中的指标数据进行聚合处理。
- 实时监控系统和报警系统读取聚合数据作展示以及报警处理。

4. CDC(数据变更捕获)
CDC(数据变更捕获)用来将数据库中的发生的更改以流的形式传输到其他系统以进行复制或者缓存以及索引更新等。
Kafka 中有一个连接器组件可以支持 CDC 功能,它需要和具体的数据源结合起来使用。数据源可以分成两种:源数据源( data source ,也叫作“源系统”)和目标数据源( Data Sink ,也叫作“目标系统”)。Kafka 连接器和源系统一起使用时,它会将源系统的数据导人到 Kafka 集群。Kafka 连接器和目标系统一起使用时,它会将 Kafka 集群的数据导人到目标系统。
下图展示了常见 CDC 系统的工作流程。
- 源数据源将事务日志发送到 Kafka。
- Kafka 的连接器将事务日志写入目标数据源。
- 目标数据源包含 ElasticSearch、Redis、备份数据源等。

5. 系统迁移
Kafka 可以用来作为老系统升级到新系统过程中的消息传递中间件(Kafka),以此来降低迁移风险。
例如,在一个老系统中,有购物车 V1、订单 V1、支付 V1 三个服务,现在我们需要将订单 V1 服务升级到订单 V2 服务。
下图展示了老系统迁移到新系统的工作流程。
- 先将老的订单 V1 服务进行改造接入 Kafka,并将输出结果写入 ORDER 主题。
- 新的订单 V2 服务接入 Kafka 并将输出结果写入 ORDERNEW 主题。
- 对账服务订阅 ORDER 和 ORDERNEW 两个主题并进行比较。如果它们的输出结构相同,则新服务通过测试。

6. 事件溯源
事件溯源是 Kafka 在微服务架构中的重要应用场景之一。可以用 Kafka 记录微服务间的事件,如订单创建、支付完成、发货通知等。这些事件可以被其他微服务订阅和消费,实现业务逻辑的协调和同步。
简单来说事件溯源就是将这些事件通过持久化存储在 Kafka 内部。如果发生任何故障、回滚或需要重放消息,我们都可以随时重新应用 Kafka 中的事件。
7. 消息队列
Kafka 最常见的应用场景就是作为消息队列。 Kafka 提供了一个可靠且可扩展的消息队列,可以处理大量数据。
Kafka 可以实现不同系统间的解耦和异步通信,如订单系统、支付系统、库存系统等。在这个基础上 Kafka 还可以缓存消息,提高系统的可靠性和可用性,并且可以支持多种消费模式,如点对点或发布订阅。
参考资料
 wechat
wechat