
Java 基础试题1
java 基本语法
Java是一门面向对象的编程语言 。
- 平台独立,可移植。 class 一次编译到处运行;
- 强类型语言,编译时检查,必须显示声明方法;
- 异常处理;
- 跨平台(java虚拟机);
java与c++区别
- Java 是纯粹的面向对象语言,所有的对象都继承自 java.lang.Object,C++ 兼容 C ,不但支持面向对象也支持面向过程。
- Java 通过虚拟机从而实现跨平台特性, C++ 依赖于特定的平台。
- Java 没有指针,它的引用可以理解为安全指针,而 C++ 具有和 C 一样的指针。
- Java 支持自动垃圾回收,而 C++ 需要手动回收。
- Java 不支持多重继承,只能通过实现多个接口来达到相同目的,而 C++ 支持多重继承。
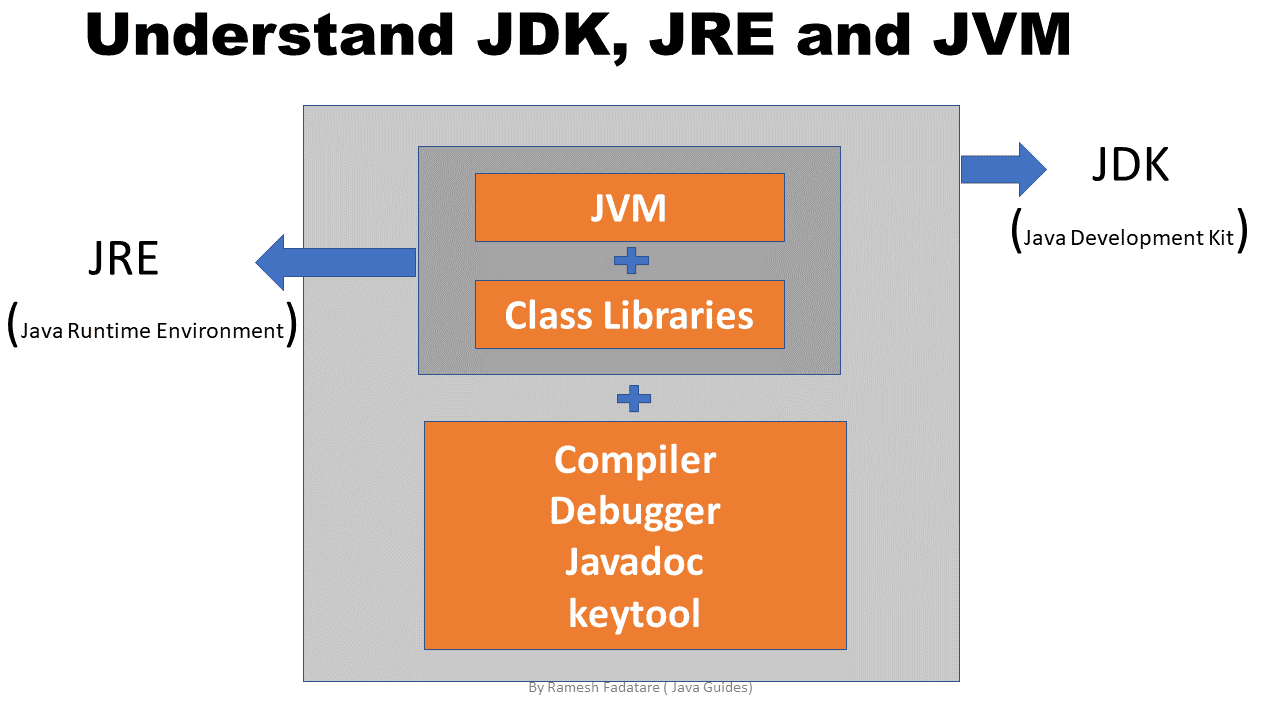
jvm/jre/jdk
- jvm : 虚拟机,class文件的运行环境;
- jre :java运行时环境,一个提供java运行的环境,包含编译后的jdk和jvm
- jdk: java dev kit (java 开发工具),一个包含常用开发工具与包的合集。
编译型语言和解释型语言
- 编译型语言: 运行前编译为二进制文件,编译后运行;优点,编译后直接运行效率高,缺点,修改后需要重新编译.
- 解释型语言: 由解释器解释运行,优点,修改后无需重新编译,缺点,运行效率低。
- 对于java,他是先编译在由jvm运行,算是上面的混合型。
面向对象与面向过程
他们是两种编程开发思想
面向过程: 1、开始游戏,2、黑子先走,3、绘制画面,4、判断输赢,5、轮到白子,6、绘制画面,7、判断输赢,8、返回步骤2,9、输出最后结果。 把上面每个步骤用分别的函数来实现,问题就解决了。
面向对象: 黑白双方棋盘系统,负责绘制画面,规则系统,负责判定诸如犯规、输赢等
面向对象特征:继承、封装、多态、抽象
六大原则:1、单一职责原则;2、开闭原则;3、里氏替换原则;4、依赖倒置原则;5、接口隔离原则;6、依赖倒置原则;
java 数据类型
数组是对象么? 是
常用基本类型
简单类型 boolean byte char short Int long float double 二进制位数 1 8 16 16 32 64 32 64 包装类 Boolean Byte Character Short Integer Long Float Double java 中boolean 由于虚拟机的实现不同,所占字节是不同的
Integer 可以用“==”比较么?
- Integer 是一个对象,所以不能用==比较,而int 是一个基本类型,可以直接用==比较。
- Integer.valueOf(128) == Integer.valueOf(128)
String 对象为什么不可变?
- 从源码来看,至少java8还是通过字符数组实现的;
- 处于线程安全的考虑;
- 字符串常量池提高效率;
- java9 将char[] 改为 byte[]
由于一般的java项目字符串的使用频率极高,处于节省内存考虑;
不过,9以后再存储前会判断是否是latin-1编码,中文使用utf16,所以对于中文而言用byte和char没有区别
strtingbuffer / stringbuilder /
- 都不可变,sbb和sbl 实际上是重新分配的数组;
- 线程安全: stringbuilder 是线程不安全,其他2个是线程安全的;
- stringJoiner 在字符串拼接方面比较便利。
new String(’abc’)创建几个对象
- 创建2个,abc是字符串字面量,初始化时分配到堆内存的字符串常量池,new 关键字在堆中创建字符串对象
- string 容量是? string.length() 返回int 所以理论上是int最大值(2^31-1) ,通过char[]计算基本上是4gb容量
- 注意:字符串常量存储在常量池中,而常量池中声明字符串是无符号的16位整形 ,即:65535,javac做了限制必须<65535 , 即65534
java 对象的深拷贝与浅拷贝
- 浅拷贝,对象内的属性对象会指向原来的对象引用.
- 深拷贝,在重写clone方法内将所有的对象属性都调用clone方法.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46public class Cat implements Cloneable {
private String name;
private Person owner;
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
public static void main(String[] args) throws CloneNotSupportedException {
Cat c = new Cat();
Person p = new Person(18, "程序员");
c.owner = p;
Cat cloneCat = (Cat) c.clone();
p.setName("jack");
System.out.println(cloneCat.owner.getName());
}
}
//深拷贝
public class Cat implements Cloneable {
private String name;
private Person owner;
protected Object clone() throws CloneNotSupportedException {
Cat c = null;
c = (Cat) super.clone();
c.owner = (Person) owner.clone();//拷贝Person对象
return c;
}
public static void main(String[] args) throws CloneNotSupportedException {
Cat c = new Cat();
Person p = new Person(18, "程序员");
c.owner = p;
Cat cloneCat = (Cat) c.clone();
p.setName("lion");
System.out.println(cloneCat.owner.getName());
}
}
2个对象的hashcode相同,equals相同么?
不一定, hashcode 是为了减少equals 比较,来提高执行效率的,hash值会存在相同的情况。 另外对于重写eq方法时,一定也要重写hashcode方法,防止在使用hash集合或map时结果不一致。
java类实例化顺序
- 静态属性,静态代码块
- 普通属性,普通代码块
- 构造方法
1 |
|
java 中的常见关键字
static 修饰方法,类的属性变量, static块
被static声明的变量,被所有的对象共享,在初始化时只保留一个副本,非static的变量在每次实例化时都会创建新的变量副本,互不影响。
static 方法 不依赖对象,不需要实例化对象。
static 代码块 在类加载阶段只运行一次,整个运行期间不会在执行。final
- 声明在变量上表示不可修改;
- 声明在方法上不可被重写;
- 声明在class上不可继承;
this / super
this , 表示对象自己的引用, super 表示父类对象引用;final, finally, finalize 的区别
finally 是异常处理的表达式部分,finally包裹部分总是被执行(极端的程序终止例外);
finalize ,是一个object方法,在sys.gc 时调用。但不保证一定会调用到。
接口与抽象类的区别?
- 从语法角度:
抽象类的成员变量可以是私有的,接口不能声明private;
可继承1个抽象类,实现多个接口; - 设计层面:
抽象类更多的是基于整体的抽象,包括属性,方法。 而接口多是对于行为的抽象(即方法),抽象了代表“是不是”,而接口更多表达某种能力“有没有”。
常见异常
- RuntimeException
indexOutOfBoundsExce / NullPointerExce / NumberFormatteExce
- checkedException
NoSuchFileExce / ClassNotFoundExce / IlleagalAccessExce
- Error
jvm 无法解决的错误,诸如 Stack Overflow , oom 等。
bio/nio/aio
- bio,传统的阻塞id
- nio,非阻塞io, 多路复用,轮训注册 channel
- aio,异步id, read 和write 都是异步的, 在io结束后通知进程。Future
实现 Serializable 接口之后,为什么还要显示指定 serialVersionUID 的值?
sUID 如果没有指定的话,jvm在序列化和反序列化时都会重新创建,如果class没有修改的话一般不会出现问题,但是代码是要不断迭代的,所以最好显示的指定sUID值,防止报错。
transient 关键字
transient 关键字,描述序列化和反序列化时是否处理该值。标记transient的属性将被忽略.
java 集合
常见的集合有哪些?
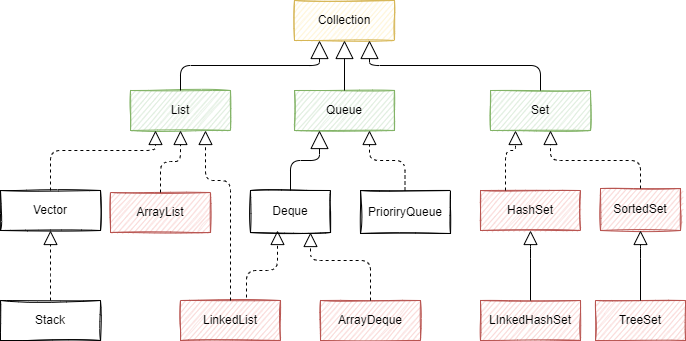
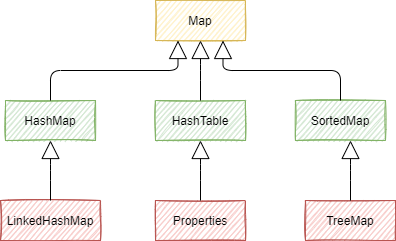
java目前主要有2个集合接口: Collection 和 Map 。
Collection:List,Set,Queue
Map: HashMap , HashTable 。
List 代表有序集合,Set 代表无需集合(且不能重复), Queue 队列集合,Map 用来存储 key-value 对的集合。 较为常用的集合实现类有: ArrayList,LinkedList,HashMap,HashTable,TreeMap,TreeSet等。
list ,set ,map 区别
- list 由索引,有顺序,允许null 和重复;
- set 不允许重复,允许null(只能1个);
- list 的底层由数组或者链表实现, set 和map 是基于hash 或 红黑树实现;
arrayList 详细描述
arrayList 底层由动态数组实现。
arrayList的动态扩容:
默认1.5倍的原数组,add元素前 会计算扩容size,后新建数组,在将原数组拷贝到新数组。
1 |
|
arraylist 在遍历中删除元素?
不建议,首先 arraylist 是线程不安全的,其次这样会导致 快速失败(fast-fail)。
可以使用迭代器删除。
arraylist , linkedlist,vector 区别
- vector 是线程安全的,不过一般不适用效率较低。
- linked 基于链表实现。
- 对于 随机的 get set 操作,arraylist 效率是高于linkedlist (链表需要移动遍历指针查找);
- 新增和删除元素方面, linkedlist 是优于数组的(arraylist 需要扩容和拷贝数组)
HashMap 概述?
另一篇文章 HashMap 源码解析
LinkedHashMap底层原理?
HashMap是无序的,迭代HashMap所得到元素的顺序并不是它们最初放到HashMap的顺序,即不能保持它们的插入顺序。LinkedHashMap继承于HashMap,是HashMap和LinkedList的融合体,具备两者的特性。每次put操作都会将entry插入到双向链表的尾部。
LinkedHashMap 代码实现: 从源码中得知,继承hashmap ,并且使用了一种类似装饰器(切面)的方式,put 方法使用的是hashmap的put方法,并在方法内 调用了 newNode方法,linkedHashMap 子类重写了 newNode等方法,从而实现在put方法的前后 记录parent节点和next节点实现有序Map。是 一种很巧妙的实现方式类似一种钩子调用。
代码:
1 | // linkedHashMap 重写该方法 |
1 |
|
TreeMap 介绍?
TreeMap的特点:TreeMap是有序的key-value集合,通过红黑树实现。根据键的自然顺序进行排序或根据提供的Comparator进行排序。
TreeMap继承了AbstractMap,实现了NavigableMap接口,支持一系列的导航方法,给定具体搜索目标,可以返回最接近的匹配项。如floorEntry()、ceilingEntry()分别返回小于等于、大于等于给定键关联的Map.Entry()对象,不存在则返回null。lowerKey()、floorKey、ceilingKey、higherKey()只返回关联的key。
HashSet 原理?
- 特征
无法保证元素顺序
允许null值
非线程安全 - 实现原理
HashSet实际上是一个HashMap实例,都是一个存放链表的数组。它不保证存储元素的迭代顺序;此类允许使用null元素。HashSet中不允许有重复元素,这是因为HashSet是基于HashMap实现的,HashSet中的元素都存放在HashMap的key上面,而value中的值都是统一的一个固定对象private static final Object PRESENT = new Object();
HashSet中add方法调用的是底层HashMap中的put()方法,而如果是在HashMap中调用put,首先会判断key是否存在,如果key存在则修改value值,如果key不存在这插入这个key-value。而在set中,因为value值没有用,也就不存在修改value值的说法,因此往HashSet中添加元素,首先判断元素(也就是key)是否存在,如果不存在这插入,如果存在着不插入,这样HashSet中就不存在重复值。
所以判断key是否存在就要重写元素的类的equals()和hashCode()方法,当向Set中添加对象时,首先调用此对象所在类的hashCode()方法,计算次对象的哈希值,此哈希值决定了此对象在Set中存放的位置;若此位置没有被存储对象则直接存储,若已有对象则通过对象所在类的equals()比较两个对象是否相同,相同则不能被添加。
1 | import java.util.*; |
HashSet的底层通过HashMap实现的,而HashMap在1.7之前使用的是数组+链表实现,在1.8+使用的数组+链表+红黑树实现。其实也可以这样理解,HashSet的底层实现和HashMap使用的是相同的方式,因为Map是无序的,因此HashSet也无法保证顺序。HashSet的方法也是借助HashMap的方法来实现的。
HashSet、LinkedHashSet 和 TreeSet 的区别?
- HashSet 是 Set 接口的主要实现类 ,HashSet 的底层是 HashMap,线程不安全的,可以存储 null 值;
- LinkedHashSet 是 HashSet 的子类,能够按照添加的顺/序遍历;
- TreeSet 底层使用红黑树,能够按照添加元素的顺序进行遍历,排序的方式可以自定义。
什么是fail fast?
fast-fail是Java集合的一种错误机制。当多个线程对同一个集合进行操作时,就有可能会产生fast-fail事件。
例如:当线程a正通过iterator遍历集合时,另一个线程b修改了集合的内容,此时modCount(记录集合操作过程的修改次数)会加1,不等于expectedModCount,那么线程a访问集合的时候,就会抛出ConcurrentModificationException,产生fast-fail事件。边遍历边修改集合也会产生fast-fail事件。
解决方法:
- 使用Colletions.synchronizedList方法或在修改集合内容的地方加上synchronized。这样的话,增删集合内容的同步锁会阻塞遍历操作,影响性能。
- 使用CopyOnWriteArrayList来替换ArrayList。在对CopyOnWriteArrayList进行修改操作的时候,会拷贝一个新的数组,对新的数组进行操作,操作完成后再把引用移到新的数组。
什么是fail safe?
采用安全失败机制的集合容器,在遍历时不是直接在集合内容上访问的,而是先复制原有集合内容,在拷贝的集合上进行遍历。java.util.concurrent包下的容器都是安全失败,可以在多线程下并发使用,并发修改。
原理:由于迭代时是对原集合的拷贝进行遍历,所以在遍历过程中对原集合所作的修改并不能被迭代器检测到,所以不会触发Concurrent Modification Exception。
缺点: 基于拷贝内容的优点是避免了Concurrent Modification Exception,但同样地,迭代器并不能访问到修改后的内容,即:迭代器遍历的是开始遍历那一刻拿到的集合拷贝,在遍历期间原集合发生的修改迭s代器是不知道的。
线程安全的集合和不安全的集合?
线程安全的: vector、HashTable、 concurrentHashMap、Stack(继承vector)
线程不安全的: ArrayList、HashMap、HashTable、HashSet、TreeSet、TreeMap、LinkedList
Iterator 作用? 和 listIterator 区别?
iterator 是用一种更抽象的方式来遍历集合,他不需要了解具体的集合实现,java中大部分集合都实现了iterator,他的特点是更加安全,如果同时操作改变集合会抛出异常。
listiterator 算是iterator的一个增强版本,Iterator和ListIterator都是Java集合框架中用于遍历集合的接口,但它们有一些关键区别:
通用性:
- Iterator:这是所有集合类(如List, Set, Map等)通用的遍历接口,只支持向前遍历。
- ListIterator:是Iterator的子接口,专为List接口的实现类设计,提供了更丰富的功能,包括双向遍历和索引操作。
遍历方向:
- Iterator:只能向前遍历集合。
- ListIterator:除了向前遍历,还可以向后遍历,支持hasPrevious()和previous()方法。
元素操作:
- Iterator:仅提供remove()方法移除元素,不能添加或修改元素。
- ListIterator:除了remove(),还提供add()方法添加元素到列表中,以及set()方法替换当前元素。
索引访问:
- Iterator:不提供直接获取元素索引的方法。
- ListIterator:可以获取当前元素的索引(nextIndex())和前一个元素的索引(previousIndex())。
初始位置:
- Iterator:通常从集合的开始或结束开始遍历。
- ListIterator:可以指定开始遍历的位置,可以是从开始、结束或者集合中的任意位置开始。
迭代顺序:
- Iterator:通常按照集合的自然顺序遍历。
- ListIterator:可以按照List的指定顺序遍历,这可能涉及到插入点的考虑。
总的来说,ListIterator提供了比Iterator更高级的遍历和操作能力,特别适合需要知道元素索引或需要双向遍历的场景。
创建一个不可改变的集合类?
1 | List<String> list = new ArrayList<>(); |
有哪些并发集合?
JDK中,大部分并发集合容器在 java.util.concurrent包中。
- concurrentHashMap 是一个线程安全,替代HashMap;
多线程环境下,使用Hashmap进行put操作会引起死循环,应该使用支持多线程的 ConcurrentHashMap。JDK1.8 ConcurrentHashMap取消了segment分段锁,而采用CAS和synchronized来保证并发安全。数据结构采用数组+链表/红黑二叉树。synchronized只锁定当前链表或红黑二叉树的首节点,相比1.7锁定HashEntry数组,锁粒度更小,支持更高的并发量。当链表长度过长时,Node会转换成TreeNode,提高查找速度。
ConcurrentHashMap 和 Hashtable 的区别?
Hashtable通过使用synchronized修饰方法的方式来实现多线程同步,因此,Hashtable的同步会锁住整个数组。在高并发的情况下,性能会非常差。ConcurrentHashMap采用了更细粒度的锁来提高在并发情况下的效率。注:synchronized容器(同步容器)也是通过synchronized关键字来实现线程安全,在使用的时候会对所有的数据加锁。
Hashtable默认的大小为11,当达到阈值后,每次按照下面的公式对容量进行扩充:newCapacity = oldCapacity * 2 + 1。ConcurrentHashMap默认大小是16,扩容时容量扩大为原来的2倍。
copyOnWriteArrayList 线程安全的List, 读多写少的场合性能高于vector;
CopyOnWriteArrayList相当于线程安全的ArrayList,使用了一种叫写时复制的方法,当有新元素add到CopyOnWriteArrayList时,先从原有的数组中拷贝一份出来,然后在新的数组做写操作,写完之后,再将原来的数组引用指向到新数组。
CopyOnWriteArrayList中add方法添加的时候是需要加锁的,保证同步,避免了多线程写的时候复制出多个副本。读的时候不需要加锁,如果读的时候有其他线程正在向CopyOnWriteArrayList添加数据,还是可以读到旧的数据。
优点: 读操作性能很高,不需要同步措施;
缺点:占用内存(先复制集合),数据实时性(脏读),这一点vector 是在读的时候也采用了同步锁,他们的区别就在这里。concurrentLinkedQueue 是一个高效的并发队列,基于链表实现,可以替代 LinkedList ,非阻塞队列(注意这里的非阻塞使用的CAS方式),他是一个线程安全的非阻塞队列,在高并发编程中使用广泛。
blockingqueue 是一个阻塞的线程安全队列。
ConcurrentLinkedQueue 和 bolckingqueue 的区别是什么?
ConcurrentLinkedQueue和BlockingQueue(例如LinkedBlockingQueue)是Java并发编程中的两种不同类型的队列,它们的主要区别在于同步策略、阻塞行为以及设计理念:
同步策略:
- ConcurrentLinkedQueue:是一个非阻塞的并发队列,它使用无锁算法(通常基于CAS操作)来保证线程安全,减少了锁的使用,适合于高并发的场景。
- BlockingQueue(例如LinkedBlockingQueue):是阻塞队列,它使用锁和条件变量来实现线程间的同步,当队列为空或满时,会阻塞相应的操作,直到条件满足。
阻塞行为:
- ConcurrentLinkedQueue:不支持阻塞操作,当队列为空时,poll()方法会立即返回null,而不会阻塞。
- BlockingQueue:支持阻塞操作,如take()或put(),当队列为空时,take()会阻塞直到有元素可用,当队列满时,put()会阻塞直到有空位。
吞吐量与响应时间:
- ConcurrentLinkedQueue:在高并发情况下,由于避免了线程阻塞,通常会有更高的吞吐量,但响应时间可能比阻塞队列更不可预测。
- BlockingQueue:通过阻塞线程,可以更好地平衡生产者和消费者的处理速度,从而提供更稳定的响应时间,但吞吐量可能较低。
应用场景:
- ConcurrentLinkedQueue:适用于需要高并发、低延迟且不需要线程间阻塞同步的场景。
- BlockingQueue:适合于典型的生产者-消费者模型,需要保证线程间的协作,确保资源的有效分配。
注意2者都是线程安全的,选择哪种队列取决于具体的应用需求,如系统资源、并发级别、响应时间要求以及是否需要线程间的阻塞协调。
阻塞队列与非阻塞队列?
非阻塞队列
高效的并发队列,使用链表实现。可以看做一个线程安全的 LinkedList,通过 CAS 操作实现。
如果对队列加锁的成本较高则适合使用无锁的 ConcurrentLinkedQueue 来替代。适合在对性能要求相对较高,同时有多个线程对队列进行读写的场景。
非阻塞队列中的几种主要方法:add(E e): 将元素e插入到队列末尾,如果插入成功,则返回true;如果插入失败(即队列已满),则会抛出异常; remove():移除队首元素,若移除成功,则返回true;如果移除失败(队列为空),则会抛出异常; offer(E e):将元素e插入到队列末尾,如果插入成功,则返回true;如果插入失败(即队列已满),则返回false; poll():移除并获取队首元素,若成功,则返回队首元素;否则返回null; peek():获取队首元素,若成功,则返回队首元素;否则返回null对于非阻塞队列。
一般情况下建议使用offer、poll和peek三个方法,不建议使用add和remove方法。因为使用offer、poll和peek三个方法可以通过返回值判断操作成功与否,而使用add和remove方法却不能达到这样的效果。
阻塞队列(典型的生产者消费者)
阻塞队列是java.util.concurrent包下重要的数据结构,BlockingQueue提供了线程安全的队列访问方式:当阻塞队列进行插入数据时,如果队列已满,线程将会阻塞等待直到队列非满;从阻塞队列取数据时,如果队列已空,线程将会阻塞等待直到队列非空。
并发包下很多高级同步类的实现都是基于BlockingQueue实现的。BlockingQueue 适合用于作为数据共享的通道。使用阻塞算法的队列可以用一个锁(入队和出队用同一把锁)或两个锁(入队和出队用不同的锁)等方式来实现。
阻塞队列和一般的队列的区别就在于:多线程支持,多个线程可以安全的访问队列阻塞操作,当队列为空的时候,消费线程会阻塞等待队列不为空;当队列满了的时候,生产线程就会阻塞直到队列不满
主要方法:
| 方法\处理方式 | 抛出异常 | 返回特殊值 | 一直阻塞 | 超时退出 |
|---|---|---|---|---|
| 插入 | add(e) | offer(e) | put(e) | offer(e,time,unit) |
| 移除 | remove() | poll() | take() | poll(time,unit) |
| 检查 获取 | element() | peek() | 不可用 | 不可用 |
JDK 7 提供了7个阻塞队列,如下
1、ArrayBlockingQueue
有界阻塞队列,底层采用数组实现。ArrayBlockingQueue 一旦创建,容量不能改变。其并发控制采用可重入锁来控制,不管是插入操作还是读取操作,都需要获取到锁才能进行操作。此队列按照先进先出(FIFO)的原则对元素进行排序。默认情况下不能保证线程访问队列的公平性,参数fair可用于设置线程是否公平访问队列。为了保证公平性,通常会降低吞吐量。
1 | private static ArrayBlockingQueue<Integer> blockingQueue = new ArrayBlockingQueue<Integer>(10,true);//fair |
2、LinkedBlockingQueue
LinkedBlockingQueue是一个用单向链表实现的有界阻塞队列,可以当做无界队列也可以当做有界队列来使用。通常在创建 LinkedBlockingQueue 对象时,会指定队列最大的容量。此队列的默认和最大长度为Integer.MAX_VALUE。此队列按照先进先出的原则对元素进行排序。与 ArrayBlockingQueue 相比起来具有更高的吞吐量。
3、PriorityBlockingQueue
支持优先级的无界阻塞队列。默认情况下元素采取自然顺序升序排列。也可以自定义类实现compareTo()方法来指定元素排序规则,或者初始化PriorityBlockingQueue时,指定构造参数Comparator来进行排序。
PriorityBlockingQueue 只能指定初始的队列大小,后面插入元素的时候,如果空间不够的话会自动扩容。
PriorityQueue 的线程安全版本。不可以插入 null 值,同时,插入队列的对象必须是可比较大小的(comparable),否则报 ClassCastException 异常。它的插入操作 put 方法不会 block,因为它是无界队列(take 方法在队列为空的时候会阻塞)。
4、DelayQueue
支持延时获取元素的无界阻塞队列。队列使用PriorityBlockingQueue来实现。队列中的元素必须实现Delayed接口,在创建元素时可以指定多久才能从队列中获取当前元素。只有在延迟期满时才能从队列中提取元素。
5、SynchronousQueue
不存储元素的阻塞队列,每一个put必须等待一个take操作,否则不能继续添加元素。支持公平访问队列。
SynchronousQueue可以看成是一个传球手,负责把生产者线程处理的数据直接传递给消费者线程。队列本身不存储任何元素,非常适合传递性场景。SynchronousQueue的吞吐量高于LinkedBlockingQueue和ArrayBlockingQueue。
6、LinkedTransferQueue
由链表结构组成的无界阻塞TransferQueue队列。相对于其他阻塞队列,多了tryTransfer和transfer方法。
transfer方法:如果当前有消费者正在等待接收元素(take或者待时间限制的poll方法),transfer可以把生产者传入的元素立刻传给消费者。如果没有消费者等待接收元素,则将元素放在队列的tail节点,并等到该元素被消费者消费了才返回。
tryTransfer方法:用来试探生产者传入的元素能否直接传给消费者。如果没有消费者在等待,则返回false。和上述方法的区别是该方法无论消费者是否接收,方法立即返回。而transfer方法是必须等到消费者消费了才返回。
JDK使用通知模式实现阻塞队列。所谓通知模式,就是当生产者往满的队列里添加元素时会阻塞生产者,当消费者消费了一个队列中的元素后,会通知生产者当前队列可用。
ArrayBlockingQueue使用Condition来实现:
1 | private final Condition notEmpty; |
java8 新增特性
函数式编程
函数式编程是8推出的最大的新增特性,对后续的很多框架编写提供了便利。
- Lambda 表达式:
Lambda 表达式是一种简洁的方式来表示匿名函数,即没有名称的函数。它们可以赋值给变量,作为参数传递,或者作为返回值。Lambda 的语法形式是 (parameters) -> expression 或 (parameters) -> { statements; }。
1 | List<String> names = Arrays.asList("dabin", "tyson", "sophia"); |
- 函数式接口:
为了使 Lambda 表达式可用,Java 引入了函数式接口,这是一个只有一个抽象方法的接口。Runnable, Callable, Comparator 和 Function 等都是常见的函数式接口。Lambda 表达式可以直接转换为这些接口的实例。
1 | 上面lambda的例子 |
- 函数式编程接口:
java.util.function 包提供了大量预定义的函数式接口,如 Function<T, R>(接受一个类型 T 的参数并返回 R 类型的结果)、Predicate(接受一个 T 类型的参数并返回一个布尔值)、Consumer (接受一个 T 类型的参数,无返回值)等。
function包下的函数接口, 很多在streamApi中得到了应用。如:排序、过滤集合、条件排序、集合转化、去重复等功能。
Funciton 接受一个参数返回一个结果,apply方法
1
2
3
4
5
6
7
8
9
10
public void testFunc(){
Function<Integer,String> converter = (num) -> {
int term = num+10;
return Integer.toString(term);
};
String result = converter.apply(3);
System.out.println(result);
}Predicate 接受1个参数返回boolean, 接口方法test()
1
2
3
4
5
6
public void testPredicate(){
Predicate<String> predicate = (s -> s.length() > 0);
Boolean result = predicate.test("lwd");
System.out.println(result);
}Consumer 接受一个值,不返回任何结果,accept()方法
1
2
3
4
5
6
public void testConsumer(){
Consumer<String> consumer = (s -> System.out.println(s));
consumer.accept("lwd");
}counsumer 常用在集合遍历中的数据处理.
如:list.stream().forEach(System.out::println);Supplier 不接受任何值,只返回结果.
1
2
3
4
5
6
7
8
9
10
public void testSupplier(){
Supplier<String> supplier = () -> {
System.out.println("aaaa");
return "qqqq";
};
String result = supplier.get();
System.out.println(result);
}Predicate:表示一个布尔型的函数,接受一个参数,返回一个布尔值,例如(x) -> x > 0。
Consumer:表示一个消费型的函数,接受一个参数,无返回值,例如(x) -> System.out.println(x)。
Function<T, R>:表示一个映射型的函数,接受一个参数,返回一个结果,例如(x) -> x * 2。
Supplier:表示一个供给型的函数,无参数,返回一个结果,例如() -> Math.random()。
下面是其他一些应用例子:
1 |
|
1 | Comparator<Person> comparator = Comparator.comparing(p -> p.firstName); |
Stream API:
Stream API 提供了一种函数式编程风格处理集合数据的方式,支持诸如过滤、映射、聚合等操作。它允许你对数据进行懒加载和并行计算,极大地提高了代码的简洁性和性能。
Stream中有两个核心概念,一个是流,一个是操作(operation)
流:即一个数据序列,可以包含多个操作;
流的操作(operation)分2类: 1 中间操作 2 中断操作;
常见的中间操作有: filter、map、sorted、distinct、limit 等
常见的终端操作有: forEach、collect、reduce 等
这些方法可以组合使用,构成一个操作链,最终返回一个最终结果。
操作链的执行是 惰性求值 的,即只有在需要计算结果时才进行计算。这种方式可以避免不必要的计算,并提高代码的执行效率。
创建stream
可以通过 集合、数组、IO、生成器等api创建stream对象。1
2List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
Stream<Integer> stream = numbers.stream();中间操作
Stream 对象提供了多种中间操作方法,可以对 Stream 对象进行过滤、映射、排序、去重、限制等操作,常用方法包括:
filter(Predicate
predicate):根据条件过滤 Stream 对象中的元素。 map(Function<T, R> mapper):将 Stream 对象中的元素映射到新的值。
sorted(Comparator
comparator):对 Stream 对象中的元素进行排序。 distinct():去重 Stream 对象中的元素。
limit(long maxSize):限制 Stream 对象中元素的数量。
终端操作
Stream 对象提供了多种终端操作方法,可以将 Stream 对象转换为集合、数组、Map 对象,或者进行聚合操作,常用方法包括:
- collect(Collector<T, A, R> collector):将 Stream 对象中的元素收集到集合、数组、Map 对象等中。
- reduce(T identity, BinaryOperator
accumulator):对 Stream 对象中的元素进行聚合操作。 - forEach(Consumer
action):对 Stream 对象中的元素进行遍历操作。
优缺点
- 简洁、高效、易于维护:Stream API 的方法链式调用,可以使代码更加简洁、易于阅读和维护。
- 支持并行处理:Stream API 支持对集合和数组中的元素进行并行处理,提高了处理效率。
- 支持惰性求值:Stream API 的操作是惰性求值的,只有在需要计算结果时才进行计算,避免了不必要的计算。
- 支持多种数据源:Stream API 可以处理多种不同类型的数据源,例如集合、数组、IO 流、生成器等。
- 支持多种操作:Stream API 提供了多种中间操作方法和终端操作方法,可以对数据进行过滤、映射、排序、去重、聚合等操作。
- 可以组合使用:Stream API 的操作可以组合使用,构成一个操作链,最终返回一个最终结果。
Filter 过滤
Filter的入参是一个Predicate,用于筛选出我们需要的集合元素。原集合不变。filter 会过滤掉不符合特定条件的,下面的代码会过滤掉nameList中不以大彬开头的字符串。
1 |
|
Sorted 排序
自然排序,不改变原集合,返回排序后的集合。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
public class StreamTest1 {
public static void main(String[] args) {
List<String> nameList = new ArrayList<>();
nameList.add("大3");
nameList.add("大1");
nameList.add("大2");
nameList.add("aaa");
nameList.add("bbb");
nameList
.stream()
.filter((s) -> s.startsWith("大"))
.sorted()
.forEach(System.out::println);
}
/**
* output
* 大彬1
* 大彬2
* 大彬3
*/
}
逆序排序:
1 | nameList |
对元素某个字段排序:
1 | list.stream().sorted(Comparator.comparing(Student::getAge).reversed()); |
Map 转换
将每个字符串转为大写。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17public class StreamTest2 {
public static void main(String[] args) {
List<String> nameList = new ArrayList<>();
nameList.add("aaa");
nameList.add("bbb");
nameList
.stream()
.map(String::toUpperCase)
.forEach(System.out::println);
}
/**
* output
* AAA
* BBB
*/
}
Match 匹配
验证 nameList 中的字符串是否有以张开头的。
1 |
|
Count 计数
统计 stream 流中的元素总数,返回值是 long 类型。
1 | public class StreamTest4 { |
Reduce
类似拼接。可以实现将 list 归约成一个值。它的返回类型是 Optional 类型。
1 |
|
flatMap
flatMap 用于将多个Stream连接成一个Stream。
下面的例子,把几个小的list转换到一个大的list。
1 |
|
下面的例子中,将words数组中的元素按照字符拆分,然后对字符去重。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
public class StreamTest7 {
public static void main(String[] args) {
List<String> words = new ArrayList<String>();
words.add("我军能打胜仗");
words.add("我军作风优良");
//将words数组中的元素按照字符拆分,然后对字符去重
List<String> stringList = words.stream()
.flatMap(word -> Arrays.stream(word.split("")))
.distinct()
.collect(Collectors.toList());
stringList.forEach(e -> System.out.print(e + " "));
}
/**
* output
* 我, 军, 能, 打, 胜, 仗, 作, 风, 优, 良,
*/
}
方法引用:
方法引用允许你直接引用已有的方法作为 Lambda 表达式的实现,无需手动编写函数体。高阶函数:
高阶函数是可以接受一个或多个函数作为参数,或者返回一个函数的函数。在 Java 中,你可以使用 Lambda 表达式来实现高阶函数。Optional 类:
虽然不是严格意义上的函数式编程特性,但 Optional类提供了一种处理可能为 null 的值的更安全的方式,它鼓励避免使用空指针异常,这在函数式编程中很重要,因为函数通常期望其输入是不可变的。 函数组合:
函数可以被组合在一起,形成一个新的函数,这种方式可以减少代码重复,提高代码的可读性和可维护性。
函数式接口和函数式编程以及lambda 表达式,对于开发者来说确实带来了更清晰和简洁的代码,但是函数式接口和lambda 表达是还是存在一些限制和缺点的:
兼容性问题:Java8函数式接口和Lambda表达式只能在Java8或更高版本的环境中运行,如果需要在低版本的环境中运行,就需要使用其他的工具或者框架来支持。
性能问题:Java8函数式接口和Lambda表达式在运行时会生成一些额外的对象和方法,这可能会影响程序的性能和内存占用。虽然Java虚拟机会进行一些优化和缓存,但是仍然需要注意避免过度使用或者滥用这些特性。
调试问题:Java8函数式接口和Lambda表达式在编译时会被转换为一些隐含的类和方法,这可能会导致调试时出现一些困难和混乱。例如,在断点调试时,可能会跳到一些看不懂的代码中,或者无法查看Lambda表达式中的变量值。
 wechat
wechat










