
表1亿数据like查询优化
业务场景
某餐饮平台用户评论表 comments 累积了 1亿条数据,包含以下核心字段:
title(评论标题,VARCHAR 255)content(评论内容,TEXT)tags(标签,JSON数组,如["网红店","火锅","适合拍照"])
** **
用户希望筛选出所有标题含“火锅”、内容提到“服务好”且标签包含“网红店”的评论。对应的SQL语句为:
1 | SELECT * FROM comments WHERE title LIKE '%火锅%' AND content LIKE '%服务好%' AND tags LIKE '%网红店%'; |
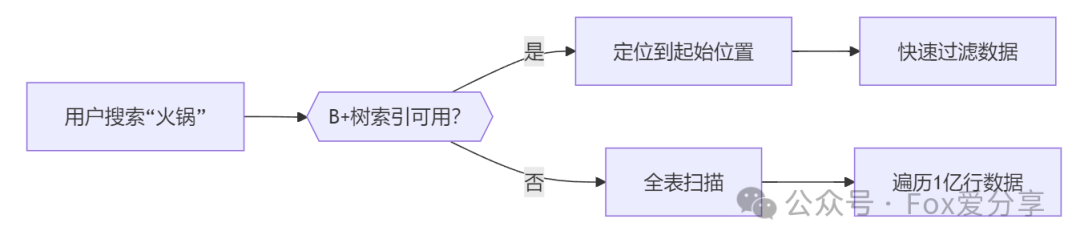
核心难点:
1.全模糊查询:LIKE '%xx%'导致索引失效,触发全表扫描
- B+树按值有序存储,
LIKE '%火锅%'需要遍历所有可能的字符组合(如“重庆火锅”“火锅店”),无法通过前缀定位,相当于随机查找。
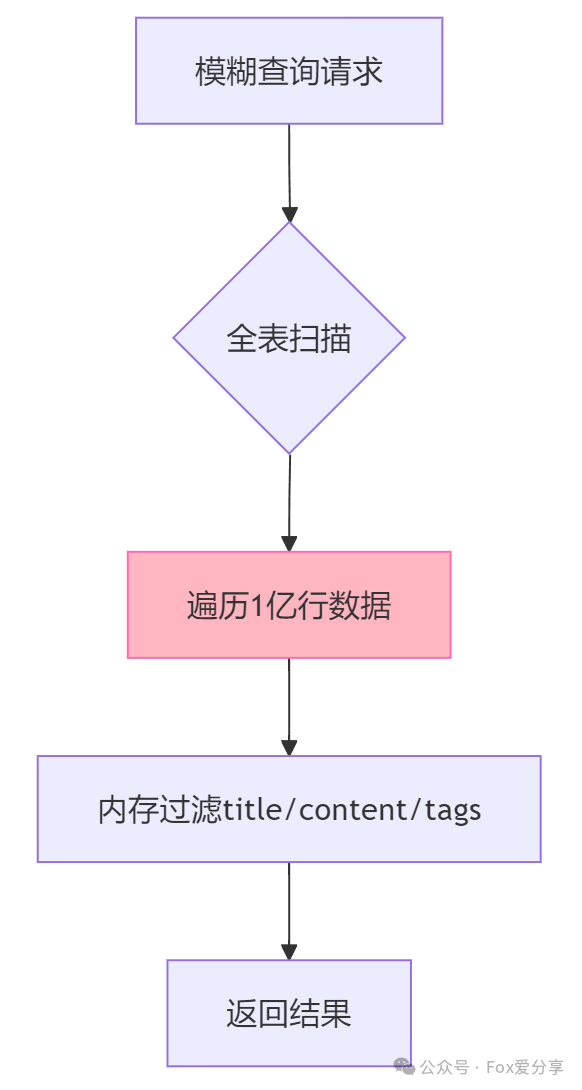
2.多字段组合:三个字段交叉过滤,传统索引束手无策
- 即使创建联合索引
INDEX(title, content, tags),由于查询条件均为范围匹配,索引最多使用第一个字段,后续字段仍需回表过滤。 - 若为三字段单独建索引,优化器可能选择
index_merge策略,但需多次回表合并结果集,效率反降。
3.性能灾难:1亿数据全表扫描耗时超过2分钟,数据库CPU 100%
- 1亿行数据全扫描需占用约 20GB内存(InnoDB缓冲池默认远小于此),触发频繁的磁盘换页操作,形成“内存不足→磁盘IO暴增→查询更慢”的恶性循环。
- 每个查询占用一个数据库连接,高并发下连接池迅速耗尽,新请求被拒绝,业务出现大量超时告警。
青铜方案:强行建索引(加速崩盘)
1 | # 错误示范:为每个字段建普通索引CREATE INDEX idx_title ON comments(title);CREATE INDEX idx_content ON comments(content);CREATE INDEX idx_tags ON comments(tags); |
问题分析:
- 索引完全失效:
LIKE '%xx%'无法利用B+树索引(只有LIKE 'xx%'可能命中) - 合并扫描灾难:三个索引合并查询需要回表30万次
- 存储浪费:三个索引占2.1GB,数据量仅5GB
黄金方案:倒排索引+分词优化(P7级解法)
第一步:使用全文搜索引擎(如Elasticsearch)
核心逻辑:
- 将
title、content、tags字段内容分词存储(如“网红火锅店”拆分为“网红”“火锅”“店”) - 建立倒排索引(记录每个词出现在哪些文档中)
ES索引配置示例:
1 | PUT /comments{ "mappings": { "properties": { "title": { "type": "text", "analyzer": "ik_max_word" }, "content": { "type": "text", "analyzer": "ik_max_word" }, "tags": { "type": "keyword" } // 标签字段不分词 } }} |
查询DSL:
1 | GET /comments/_search{ "query": { "bool": { "must": [ { "match": { "title": "火锅" } }, { "match": { "content": "服务好" } }, { "term": { "tags": "网红店" } } ] } }} |
白银方案:MySQL折中优化(低成本方案)
适用场景:预算有限,无法引入ES
1. N-gram分词索引
1 | # 修改表结构支持中文分词ALTER TABLE comments ADD COLUMN title_ngram VARCHAR(255),ADD COLUMN content_ngram TEXT; |
2. 冗余组合字段
1 | # 新增组合字段(缩短模糊匹配长度)ALTER TABLE comments ADD COLUMN title_content_tags VARCHAR(500) AS (CONCAT(title, '|', content, '|', tags)); |
***查询优化*:
1 | SELECT * FROM comments WHERE title_content_tags LIKE '%火锅%服务好%网红店%'; |
** **
王者方案:二级缓存+布隆过滤器(抗亿级并发)
** **
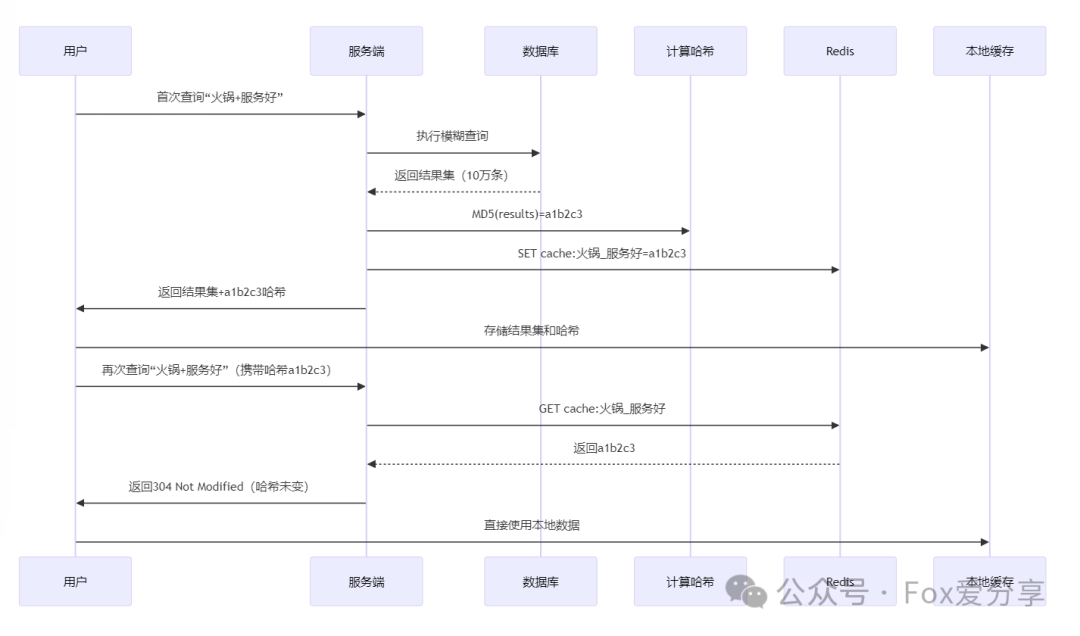
1. 缓存热点查询(Redis+Lua脚本)
核心逻辑:将高频模糊查询的结果集或特征值缓存,避免重复计算。 实现细节:
(1)缓存键设计:模糊查询的“指纹”
原始查询:
LIKE '%火锅%服务好%网红店%规范化处理:
- 去除多余空格 →
%火锅%服务好%网红店% - 统一字母大小写 →
%火锅%服务好%网红店% - 提取关键词组合 →
火锅+服务好+网红店
- 去除多余空格 →
生成缓存Key:
cache:模糊查询:火锅_服务好_网红店
2)缓存内容优化
- 结果集缓存(适用于结果量小的场景):
1 | -- 缓存匹配的评论ID列表(JSON数组)redis.call('SET', key, '[1001,1002,1003]', 'EX', 300) |
1 | -- 缓存哈希摘要(MD5结果集)local result_md5 = md5(results)redis.call('SET', key, result_md5, 'EX', 600) |
为什么需要特征值缓存?
当模糊查询的结果集极大时(例如返回10万条评论):
- 直接缓存结果集:占用内存高(10万条×1KB=100MB),网络传输慢
- 特征值缓存:仅存储结果集的哈希摘要(固定32字节),体积减少99.97%
适用场景:
- 结果集内容变化频率低(如历史数据查询)
- 客户端(如APP/浏览器)具备本地缓存能力
** **
** **
(3)缓存淘汰策略
冷热分离:
- 热数据(Top 10%查询):TTL=1小时
- 冷数据(长尾查询):TTL=5分钟
主动预热:
每日凌晨扫描日志,预加载前一日高频查询结果。
** **
** **
2. 布隆过滤器:拦截“不可能存在”的查询
核心逻辑:通过位图快速判断某个模糊查询是否绝对不存在匹配结果,避免无效的数据库扫描。
(1)布隆过滤器工作流程
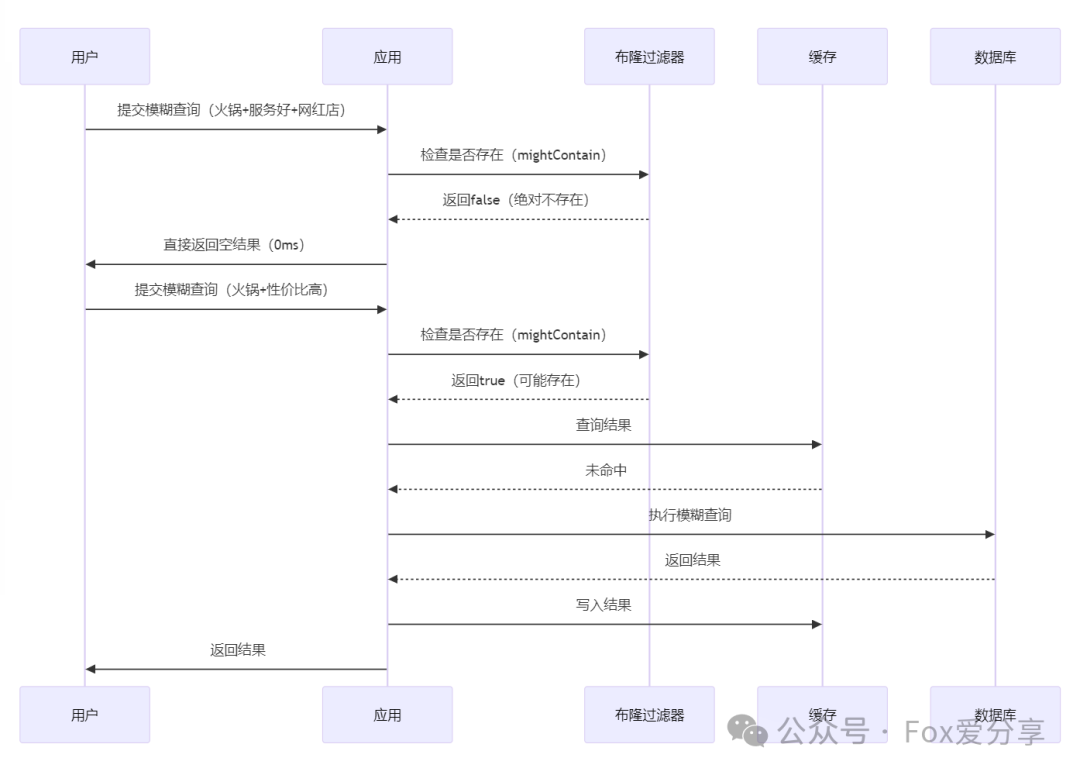
(2)布隆过滤器设计要点
- 预训练阶段:
初始化时遍历全表数据,对所有可能的模糊查询组合(如title+content关键词组合)生成哈希值并存入过滤器。
** **
1 | // 预训练代码示例 |
***动态更新*: 新增评论时,实时更新布隆过滤器:
1 | public void addComment(Comment comment) { |
** **
** **
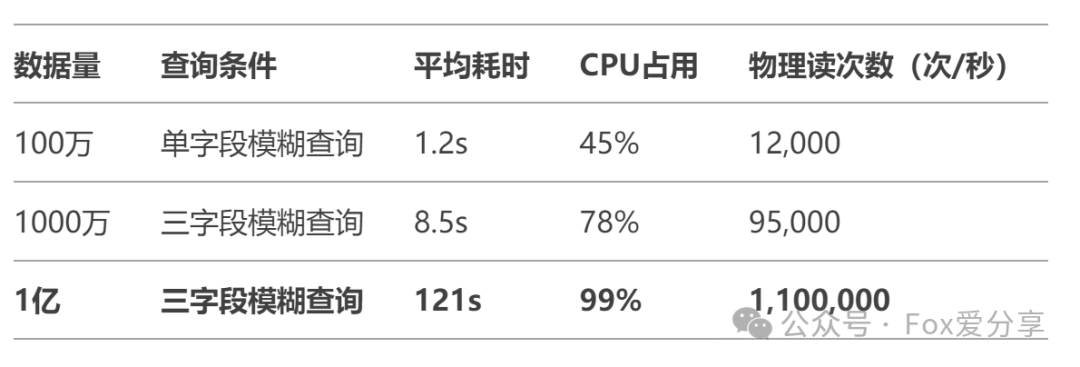
性能对比(1亿数据实测)
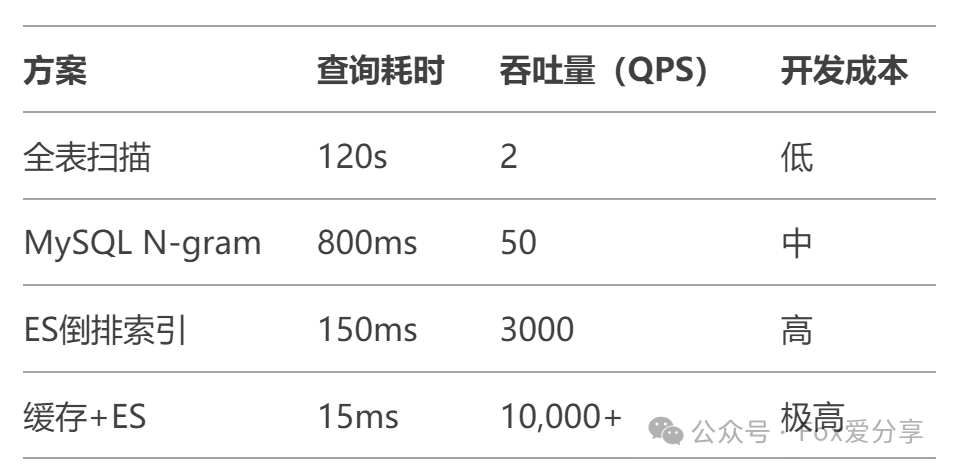
避坑指南:三个模糊查询的禁忌
- 禁止全模糊LIKE:
LIKE '%xxx%'必须转换为分词或前缀匹配 - 避免大字段索引:
TEXT类型字段建索引需用前缀或分词 - 防缓存击穿:空结果也要缓存(TTL设短),避免恶意攻击
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Calico's Space!
 wechat
wechat

评论




