

ES 深度分页问题
ES 深度分页问题及其解决方案详解1. 什么是深度分页深度分页是指在处理大数据集查询时,用户尝试访问多页数据中较后面的页面时遇到的问题。当尝试访问排序后的数据列表的第1000页或更后面的页面时,数据库需要先跳过前面数十万条记录,这一过程通常涉及大量的数据扫描和排序,极大地增加了数据库的查询负载,从而成为性能瓶颈。
ES分页查询流程大致如下:
数据存储在各个分片中,协调节点将查询请求转发给各个节点,当各个节点执行搜索后,将排序后的前N条数据返回给协调节点。
协调节点汇总各个分片返回的数据,再次排序,最终返回前N条数据给客户端。
这个流程会导致一个深度分页的问题,也就是翻页越多,性能越差,甚至导致ES出现OOM。
在分布式系统中,对结果排序的成本随分页的深度成指数上升。
从10万名高考生中查询成绩为的10001-10100位的100名考生的信息。
从上面案例中不难看出,每次有序的查询都会在每个分片中执行单独的查询,然后进行数据的二次排序,而这个二次排序的过程是发生在heap中的,也就是说当你单次查询的数量越大,那么堆内存中汇总的数据也就越多,对内存的压力也就越大。这里的单次查询的 ...

Java异步编程Future&CompletableFuture实战
Java异步编程Future&CompletableFuture实战1. allable&Future&FutureTask介绍直接继承Thread或者实现Runnable接口都可以创建线程,但是这两种方法都有一个问题就是:没有返回值,也就是不能获取执行完的结果。因此java1.5就提供了Callable接口来实现这一场景,而Future和FutureTask就可以和Callable接口配合起来使用。
1234567@FunctionalInterfacepublic interface Runnable { public abstract void run();}@FunctionalInterfacepublic interface Callable<V> { V call() throws Exception;}
Runnable 的缺陷:
不能返回一个返回值
不能抛出 checked Exception
Callable的call方法可以有返回值,可以声明抛出异常。和 ...

redis 热key
1. 理解题目:从Redis和热key说起我们先来分析一下问题本身。Redis以其高性能和低延迟而广泛应用于高并发场景,但在面对热点key时,单个分片的写入瓶颈约为20,000次/秒,读取瓶颈为100,000次/秒。在百万用户同时请求的情况下,某个热门优惠券的请求可能瞬间淹没Redis的某个分片,导致系统崩溃。
所以问题的本质就是“在高并发情况下,如何有效地解决Redis热key带来的性能瓶颈”。
2. 解决方案:使用Redis分key的策略2.1 什么是Redis分key?Redis分key是将一个热点key拆分成若干个小key,并将这些小key均匀分散到Redis集群的不同节点上。比如,将名为”coupon”的热点key拆分成多个小key(如coupon_0, coupon_1, coupon_2等),每个小key对应集群的一个分片。这样,原本由一个key承载的流量由多个key共同承担,从而提升了系统的整体性能。
2.2 如何实现Redis分key?回到我们的问题:在百万用户抢购1万张优惠券的场景中,如何通过分key来解决热key问题?
步骤如下:
1)拆 ...

nacos高并发问题
引言
场景描述:你负责的微服务系统使用Nacos作为注册中心,服务实例数超过5000个,且业务高峰期每秒有数百个服务实例发生注册、注销或心跳续约操作。近期发现Nacos集群CPU使用率持续飙升至90%以上,服务发现延迟增加,甚至出现部分实例因续约超时被标记为下线。
🔍 为什么Nacos在高并发下会”猝死”?这绝不是个例!某大厂电商系统在双11期间遭遇服务雪崩,核心问题竟出在Nacos的心跳机制上。
🧩 高并发场景下Nacos的3大死亡陷阱
陷阱1:服务端线程池挤爆原因解释想象Nacos服务端是一个餐厅,Tomcat线程池就是餐厅里的服务员。默认情况下,服务员数量只有200人(server.tomcat.max-threads=200)。
问题
当每秒有数百个心跳请求(客人)涌入时,服务员不够用,客人只能排队(请求堆积),导致CPU疯狂处理排队任务,最终爆表!
关键点
线程池是服务端处理所有请求的“劳动力”,数量不足直接导致请求处理延迟,CPU满载。
优化细节1.参数调整:
- -
1# 在nacos.conf中修改Tomcat线程池最大值server.tomcat.m ...

分布式事务的一般方案
1. 分布式基础理论1.1 CAP理论CAP 理论可以表述为,一个分布式系统最多只能同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition Tolerance)这三项中的两项。
一致性是指“所有节点同时看到相同的数据”,即更新操作成功并返回客户端完成后,所有节点在同一时间的数据完全一致,等同于所有节点拥有数据的最新版本。
可用性是指“任何时候,读写都是成功的”,即服务一直可用,而且是正常响应时间。我们平时会看到一些 IT 公司的对外宣传,比如系统稳定性已经做到 3 个 9、4 个 9,即 99.9%、99.99%,这里的 N 个 9 就是对可用性的一个描述,叫做 SLA,即服务水平协议。比如我们说月度 99.95% 的 SLA,则意味着每个月服务出现故障的时间只能占总时间的 0.05%,如果这个月是 30 天,那么就是 21.6 分钟。
分区容错性具体是指“当部分节点出现消息丢失或者分区故障的时候,分布式系统仍然能够继续运行”,即系统容忍网络出现分区,并且在遇到某节点或网络分区之间网络不可达的情况下,仍然能够对外提供满足一致性 ...

微服务架构介绍
1. 什么是微服务架构2012年,Fred George分享了题为Micro Services Architecture-small,short lived services rather than SOA的演讲。在这次演讲中,他描述了2005—2009年,他和团队成员如何将100万行的传统J2EE程序,通过解耦、自动化验证等实践,逐渐分解成20多个5000行代码的小服务。这是对微服务架构进行定义的最早版本。
从2014年起,微服务架构由Martin Fowler、Adrain Cockcroft、Neal Ford等人接力进行介绍、完善、演进、实践,一直维持着较高的热度,直到现在。关于微服务架构的定义,可以参考Martin Fowler在2014年所写的micro-services文章。在这篇文章里,Martin Fowler对微服务架构进行了定义,内容如下:
微服务架构是一种架构模式,它提倡将原本独立的单体应用,拆分成多个小型服务。这些小型服务各自独立运行,服务与服务间的通信采用轻量级通信机制(一般基于HTTP协议的RESTful API),达到互相协调、互相配合的目的。被拆分后的 ...
python 高级特性
重要知识点
生成式(推导式)的用法
123456789101112prices = { 'AAPL': 191.88, 'GOOG': 1186.96, 'IBM': 149.24, 'ORCL': 48.44, 'ACN': 166.89, 'FB': 208.09, 'SYMC': 21.29}# 用股票价格大于100元的股票构造一个新的字典prices2 = {key: value for key, value in prices.items() if value > 100}print(prices2)
说明:生成式(推导式)可以用来生成列表、集合和字典。
嵌套的列表的坑
12345678910names = ['关羽', '张飞', '赵云', '马超', ...
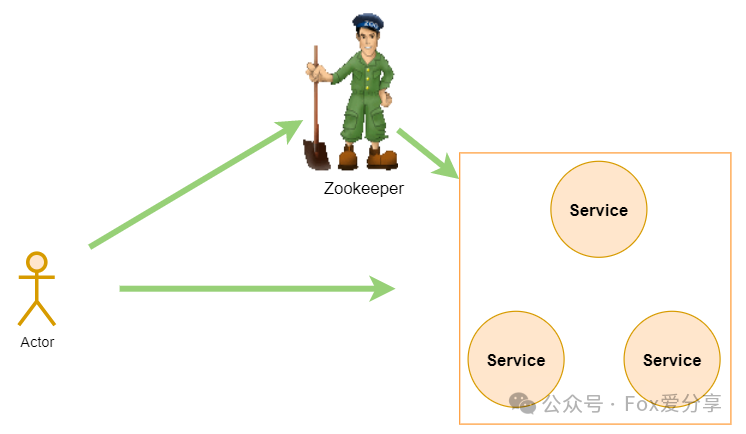
Zookeeper 结点特性详解
1. Zookeeper介绍
ZooKeeper 是一个开源的分布式协调框架,是Apache Hadoop 的一个子项目,主要用来解决分布式集群中应用系统的一致性问题。Zookeeper 的设计目标是将那些复杂且容易出错的分布式一致性服务封装起来,构成一个高效可靠的原语集,并以一系列简单易用的接口提供给用户使用。
官方:https://zookeeper.apache.org/
ZooKeeper本质上是一个分布式的小文件存储系统(Zookeeper=文件系统+监听机制)。提供基于类似于文件系统的目录树方式的数据存储,并且可以对树中的节点进行有效管理,从而用来维护和监控存储的数据的状态变化。通过监控这些数据状态的变化,从而可以达到基于数据的集群管理、统一命名服务、分布式配置管理、分布式消息队列、分布式锁、分布式协调等功能。
Zookeeper从设计模式角度来理解:是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,Zookeeper 就将负责通知已经在Zookeeper上注册的那些观察者做出相 ...
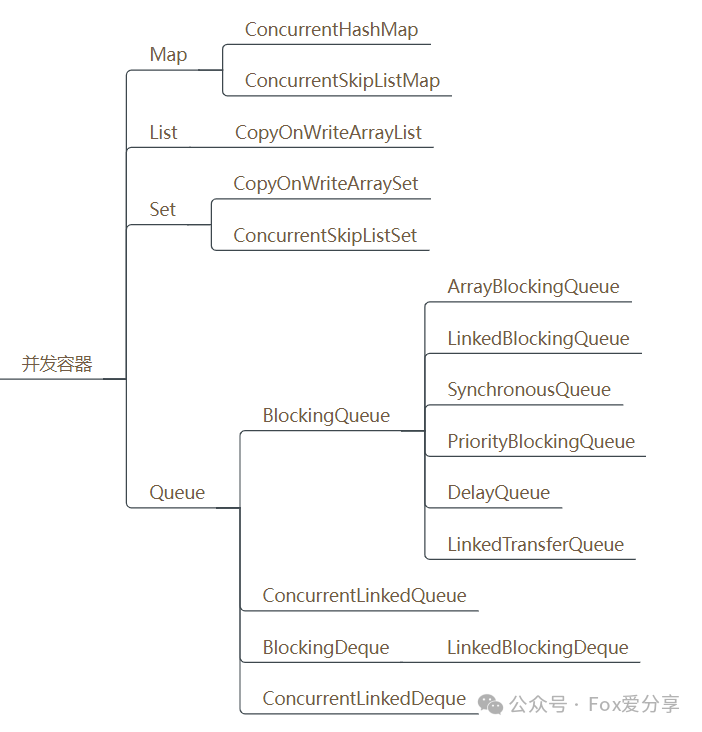
CopyOnWriteArrayList 详解
1. JUC包下的并发容器Java的集合容器框架中,主要有四大类别:List、Set、Queue、Map,大家熟知的这些集合类ArrayList、LinkedList、HashMap这些容器都是非线程安全的。
所以,Java先提供了同步容器供用户使用。同步容器可以简单地理解为通过synchronized来实现同步的容器,比如Vector、Hashtable以及SynchronizedList等容器。这样做的代价是削弱了并发性,当多个线程共同竞争容器级的锁时,吞吐量就会降低。
因此为了解决同步容器的性能问题,所以才有了并发容器。java.util.concurrent包中提供了多种并发类容器:
CopyOnWriteArrayList
对应的非并发容器:ArrayList
目标:代替Vector、synchronizedList
原理:利用高并发往往是读多写少的特性,对读操作不加锁,对写操作,先复制一份新的集合,在新的集合上面修改,然后将新集合赋值给旧的引用,并通过volatile 保证其可见性,当然写操作的锁是必不可少的了。
CopyOnWriteArraySet
对应的非并发容 ...
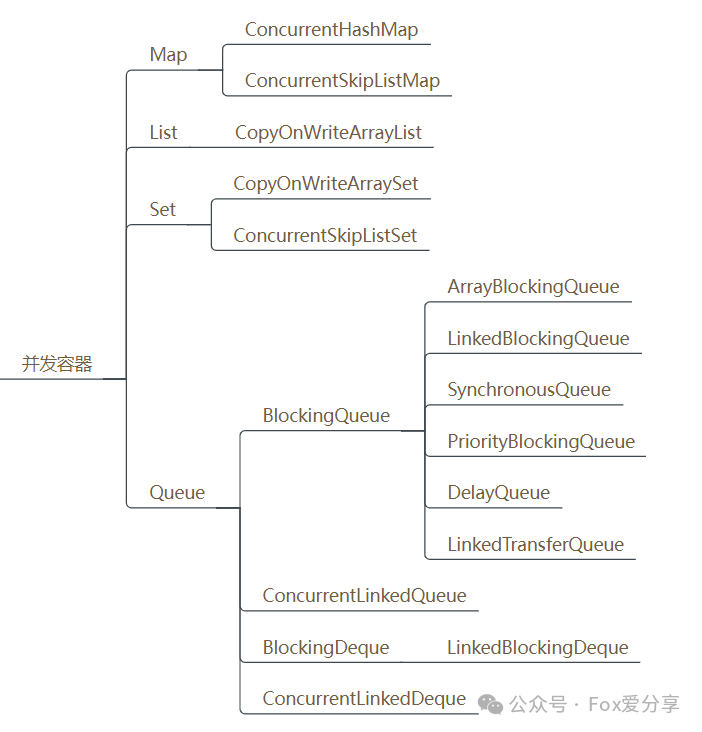
ConcurrentHashMap 和ConcurrentSkipListMap 详解
1. JUC包下的并发容器
Java的集合容器框架中,主要有四大类别:List、Set、Queue、Map,大家熟知的这些集合类ArrayList、LinkedList、HashMap这些容器都是非线程安全的。
所以,Java先提供了同步容器供用户使用。同步容器可以简单地理解为通过synchronized来实现同步的容器,比如Vector、Hashtable以及SynchronizedList等容器。这样做的代价是削弱了并发性,当多个线程共同竞争容器级的锁时,吞吐量就会降低。
因此为了解决同步容器的性能问题,所以才有了并发容器。java.util.concurrent包中提供了多种并发类容器:
CopyOnWriteArrayList
对应的非并发容器:ArrayList
目标:代替Vector、synchronizedList
原理:利用高并发往往是读多写少的特性,对读操作不加锁,对写操作,先复制一份新的集合,在新的集合上面修改,然后将新集合赋值给旧的引用,并通过volatile 保证其可见性,当然写操作的锁是必不可少的了。
CopyOnWriteArraySet
对应的非并发 ...




