
使用 Python 做数据采集(爬虫)
python数据采集
爬虫(crawler)也经常被称为网络蜘蛛(spider),是按照一定的规则自动浏览网站并获取所需信息的机器人程序(自动化脚本代码),被广泛的应用于互联网搜索引擎和数据采集。使用过互联网和浏览器的人都知道,网页中除了供用户阅读的文字信息之外,还包含一些超链接,网络爬虫正是通过网页中的超链接信息,不断获得网络上其它页面的地址,然后持续的进行数据采集。正因如此,网络数据采集的过程就像一个爬虫或者蜘蛛在网络上漫游,所以才被形象的称为爬虫或者网络蜘蛛。
主要的应用领域:
- 搜索引擎
- 新闻聚合
- 社交应用
- 舆情监控
- 行业数据
主要的实用库,以及前期的页面调研
对于数据页面或者数据接口的研究是第一步,你需要掌握html结构,页面渲染方式(ajax、iframe或者其他懒加载机制),以及安全验证(登录),session 保持、auth 等。
httpie, 一个命令行的页面请求工具,可以用于前期的page页面结构观察。
doc文档buildwith 获取网站使用技术
1
pip install buildwith
requests 库
doc文档
这是一个HTTP库,可以用于发送HTTP请求,获取响应,解析响应,获取数据。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41import requests
r = requests.get('https://www.baidu.com')
r = requests.post('https://httpbin.org/post', data={'key': 'value'})
r = requests.put('https://httpbin.org/put', data={'key': 'value'})
r = requests.delete('https://httpbin.org/delete')
r = requests.head('https://httpbin.org/get')
r = requests.options('https://httpbin.org/get')
payload = {'key1': 'value1', 'key2': 'value2'}
r = requests.get('https://httpbin.org/get', params=payload)
r.text() # 获取响应文本
r.json() # 获取响应json
r.raw() # 获取响应原始数据
r.status_code() # 获取响应状态码
r.headers() # 获取响应头
r.cookies() # 获取响应cookies
r.history() # 获取响应历史记录
r.elapsed() # 获取响应时间
r.encoding() # 获取响应编码
r.content() # 获取响应内容
r.request() # 获取请求对象
r.url() # 获取响应url
r.raise_for_status() # 获取响应状态码, 200情况下 是None
r.close()
# 获取简单流与原始流
r = requests.get('https://api.github.com/events', stream=True)
r.raw
r.raw.read(10)
#获取响应流 带buff,需要注意的与 raw不同,1 需要关闭流,2 默认已经decode gzip 和默认的压缩格式
with open(filename, 'wb') as fd:
for chunk in r.iter_content(chunk_size=128):
fd.write(chunk)
#文件上传
files = {'file': open('report.xls', 'rb')}
r = requests.post('https://httpbin.org/post', files=files)
r.text()
爬取数据的一个流程
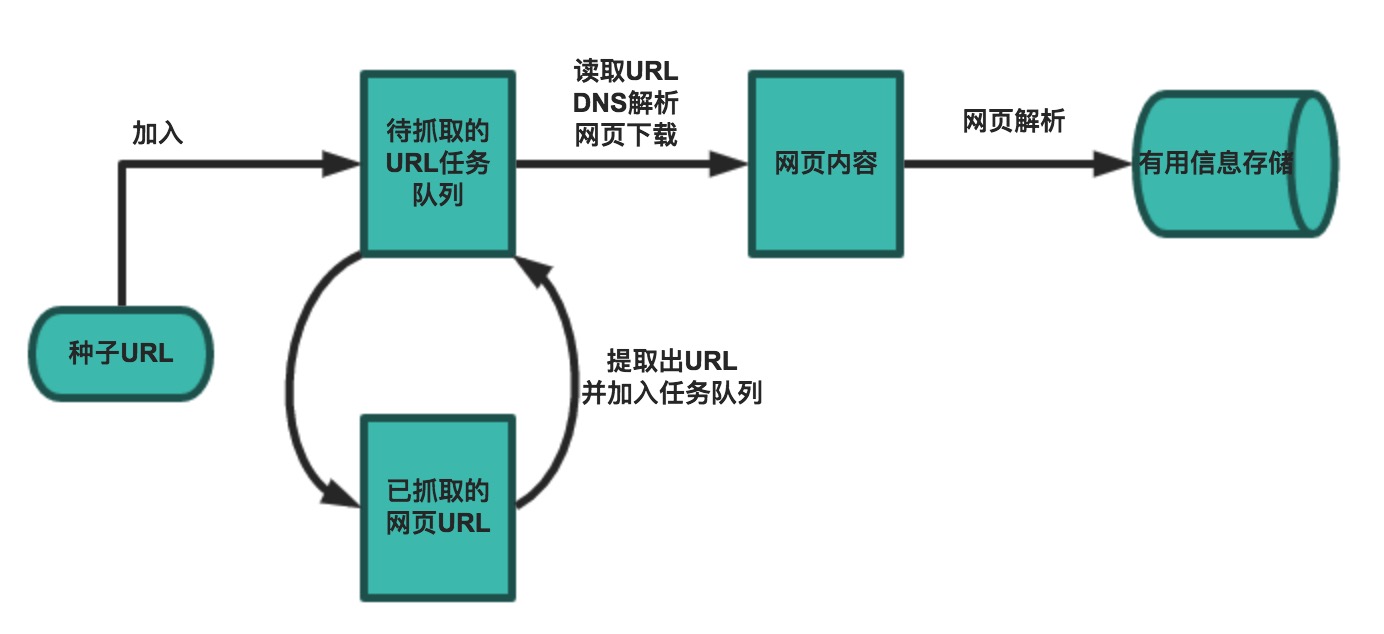
最佳实践
1. 一个最原生的requests + re 爬取网页的例子
1 |
|
使用代理
一般网站基于自身安全和带宽容量的浪费,在网关或者入口处都会有防爬和流量控制,所以需要使用代理来绕过网关,防止被封禁。
这里建议使用商业代理(免费往往不太稳定),比如:蘑菇代理、芝麻代理、快代理等
这里需要去他们的官网注册来得到代理ip。一般上面的代理服务商都会提供完善的demo给我们。其他常用的html解析库
不过这里个人提倡原生方式,类似xpath或者bef这类其实是将text生成一个内存的dom树,然后通过xpath语法提取数据,这将消耗较多内存
解析方式 对应的模块 速度 使用难度 正则表达式解析 re快 困难 XPath 解析 lxml快 一般 CSS 选择器解析 bs4或pyquery不确定 简单 BeautifulSoup
关于 BeautifulSoup ,可以参考它的官方文档。
1
2
3
4
5
6
7
8
9
10
# 创建BeautifulSoup对象
soup = bs4.BeautifulSoup(resp.text, 'lxml')
# 通过CSS选择器从页面中提取包含电影标题的span标签
title_spans = soup.select('div.info > div.hd > a > span:nth-child(1)')
# 通过CSS选择器从页面中提取包含电影评分的span标签
rank_spans = soup.select('div.info > div.bd > div > span.rating_num')
for title_span, rank_span in zip(title_spans, rank_spans):
print(title_span.text, rank_span.text)lxml 一个基于xpath的解析dom库,对于xpath 需要了解相关知识.
1
2
3
4
5
6
7
8tree = etree.HTML(resp.text)
# 通过XPath语法从页面中提取电影标题
title_spans = tree.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[1]/a/span[1]')
# 通过XPath语法从页面中提取电影评分
rank_spans = tree.xpath('//*[@id="content"]/div/div[1]/ol/li[1]/div/div[2]/div[2]/div/span[2]')
for title_span, rank_span in zip(title_spans, rank_spans):
print(title_span.text, rank_span.text)
并发在抓取中的使用
数据采集(爬虫)在python并发情形中是最符合 大量io操作的,所以使用线程和异步IO是在爬虫中比较常用的。尤其是深度采集的需求时.
- 线程池
主要片段:
下面是一个完整的demo:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17import os
from concurrent.futures import ThreadPoolExecutor
with ThreadPoolExecutor(max_workers=16) as pool:
for page in range(3):
resp = requests.get(f'https://image.so.com/zjl?ch=beauty&sn={page * 30}')
if resp.status_code == 200:
pic_dict_list = resp.json()['list']
for pic_dict in pic_dict_list:
pool.submit(download_picture, pic_dict['qhimg_url'])
```
* 异步IO
我们使用`aiohttp`将上面的代码修改为异步 I/O 的版本。为了以异步 I/O 的方式实现网络资源的获取和写文件操作,我们首先得安装三方库`aiohttp`和`aiofile`,命令如下所示。
``` shell
pip install aiohttp aiofile1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39import json
import os
import aiofile
import aiohttp
async def download_picture(session, url):
filename = url[url.rfind('/') + 1:]
async with session.get(url, ssl=False) as resp:
if resp.status == 200:
data = await resp.read()
async with aiofile.async_open(f'images/beauty/{filename}', 'wb') as file:
await file.write(data)
async def fetch_json():
async with aiohttp.ClientSession() as session:
for page in range(3):
async with session.get(
url=f'https://image.so.com/zjl?ch=beauty&sn={page * 30}',
ssl=False
) as resp:
if resp.status == 200:
json_str = await resp.text()
result = json.loads(json_str)
for pic_dict in result['list']:
await download_picture(session, pic_dict['qhimg_url'])
def main():
if not os.path.exists('images/beauty'):
os.makedirs('images/beauty')
loop = asyncio.get_event_loop()
loop.run_until_complete(fetch_json())
loop.close()
if __name__ == '__main__':
main()
- 线程池
Selenium with Python
selenium 是一个用于自动化测试的开源工具,可以驱动浏览器,模拟用户操作,实现自动化测试。 随着css和js技术发展,很多站点数据都是由前端的js渲染或者异步加载的,这个时候如果需要提取数据即可通过selenium来完成。 通过selenium可以模拟js执行,按钮点击等大多数浏览器事件。 更多详细内容可以参考官方文档。
python-selenium文档1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42import os
import time
from concurrent.futures import ThreadPoolExecutor
import requests
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
DOWNLOAD_PATH = 'images/'
def download_picture(picture_url: str):
"""
下载保存图片
:param picture_url: 图片的URL
"""
filename = picture_url[picture_url.rfind('/') + 1:]
resp = requests.get(picture_url)
with open(os.path.join(DOWNLOAD_PATH, filename), 'wb') as file:
file.write(resp.content)
if not os.path.exists(DOWNLOAD_PATH):
os.makedirs(DOWNLOAD_PATH)
browser = webdriver.Chrome()
browser.get('https://image.so.com/z?ch=beauty')
browser.implicitly_wait(10)
kw_input = browser.find_element(By.CSS_SELECTOR, 'input[name=q]')
kw_input.send_keys('苍老师')
kw_input.send_keys(Keys.ENTER)
for _ in range(10):
browser.execute_script(
'document.documentElement.scrollTop = document.documentElement.scrollHeight'
)
time.sleep(1)
imgs = browser.find_elements(By.CSS_SELECTOR, 'div.waterfall img')
with ThreadPoolExecutor(max_workers=32) as pool:
for img in imgs:
pic_url = img.get_attribute('src')
pool.submit(download_picture, pic_url)
爬虫框架Scrapy
scrapy是一个基于python的爬虫框架,可以快速实现爬虫,并且可以方便的进行数据存储。scrapy的安装可以参考官方文档。

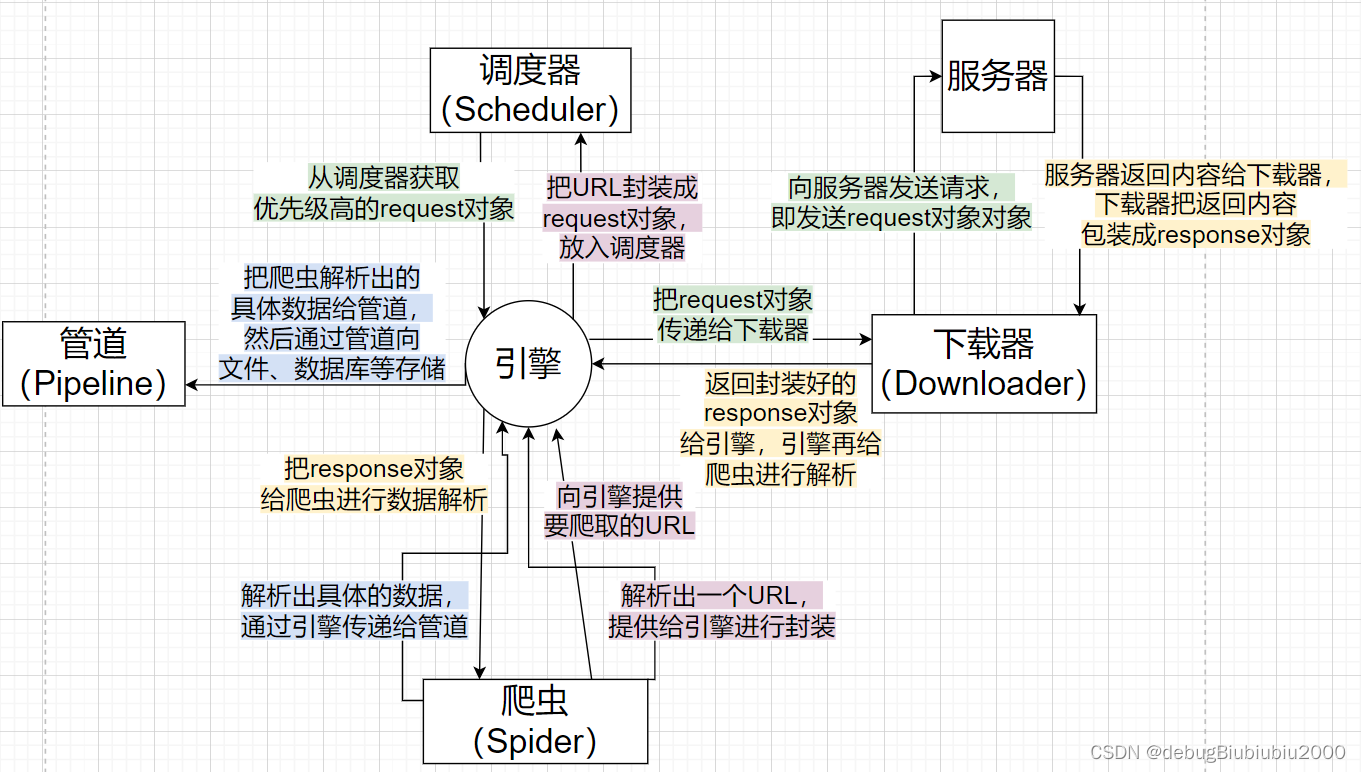
下面是一个简单的scrapydemo,未涉及部分可查看官方doc.
1 | # 创建项目 |
最后setting.py中需要配置pipeline ,以及对请求的header和浏览器的设置,防止403错误。
USER_AGENT
DEFAULT_REQUEST_HEADERS = {
“Accept”: “text/html,application/xhtml+xml,application/xml;q=0.9,/;q=0.8”,
“Accept-Language”: “en”,
}
反爬的一些应对方式
构造合理的HTTP请求头。
Accept
User-Agent
Referer
Accept-Encoding
Accept-Language
检查网站生成的Cookie。
- 有用的插件:EditThisCookie
- 如何处理脚本动态生成的Cookie
抓取动态内容。
- Selenium + WebDriver
- Chrome / Firefox - Driver
限制爬取的速度。
处理表单中的隐藏域。
- 在读取到隐藏域之前不要提交表单
- 用RoboBrowser这样的工具辅助提交表单
处理表单中的验证码。
OCR(Tesseract) - 商业项目一般不考虑
专业识别平台 - 超级鹰 / 云打码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33from hashlib import md5
class ChaoClient(object):
def __init__(self, username, password, soft_id):
self.username = username
password = password.encode('utf-8')
self.password = md5(password).hexdigest()
self.soft_id = soft_id
self.base_params = {
'user': self.username,
'pass2': self.password,
'softid': self.soft_id,
}
self.headers = {
'Connection': 'Keep-Alive',
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)',
}
def post_pic(self, im, codetype):
params = {
'codetype': codetype,
}
params.update(self.base_params)
files = {'userfile': ('captcha.jpg', im)}
r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, files=files, headers=self.headers)
return r.json()
if __name__ == '__main__':
client = ChaoClient('用户名', '密码', '软件ID')
with open('captcha.jpg', 'rb') as file:
print(client.post_pic(file, 1902))
绕开“陷阱”。
- 网页上有诱使爬虫爬取的爬取的隐藏链接(陷阱或蜜罐)
- 通过Selenium+WebDriver+Chrome判断链接是否可见或在可视区域
隐藏身份。
代理服务 - 快代理 / 讯代理 / 芝麻代理 / 蘑菇代理 / 云代理
洋葱路由 - 国内需要翻墙才能使用
1
2
3
4
5
6yum -y install tor
useradd admin -d /home/admin
passwd admin
chown -R admin:admin /home/admin
chown -R admin:admin /var/run/tor
tor
总结
python 在数据采集方面,有非常多的工具,如requests,selenium,scrapy等,但是对于一些简单的爬虫,还是使用requests比较方便。
另外,对于一些需要登录的网站,使用selenium可以模拟登录,但是对于一些需要验证码的网站,selenium可能无法解决。
- wechat





