
两千万数据,20万热点数据如何存储
一、问题本质:缓存系统的“生存游戏”
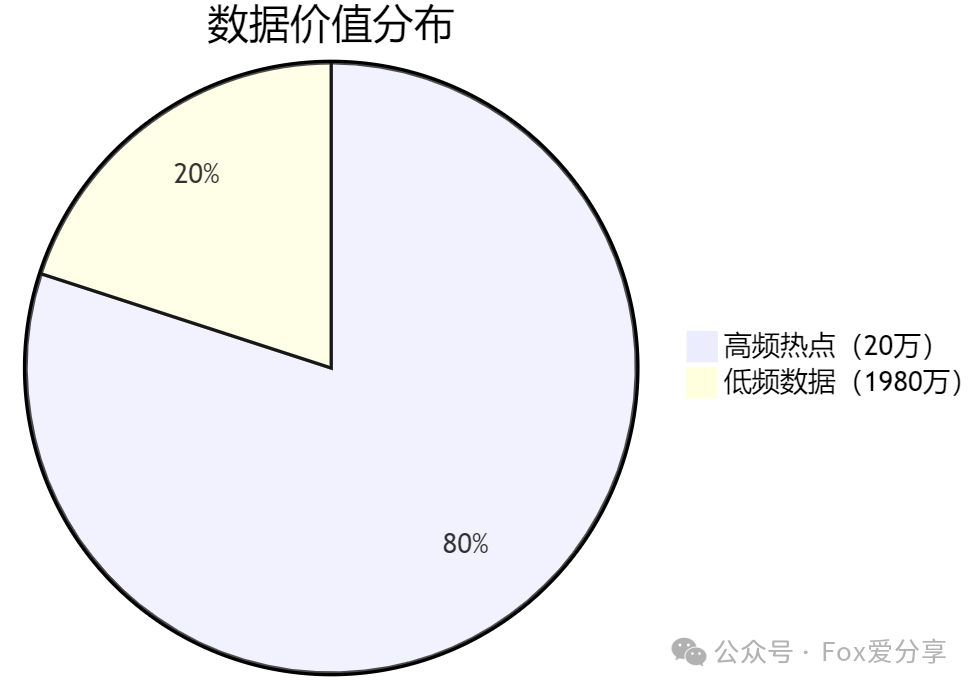
2000万数据中,只有20万是高频访问的“顶流”,剩下1980万都是“冷数据”。这像一场生存游戏——如何让Redis精准淘汰“冷数据”,长期保留“热数据”?
以下数据暴露核心矛盾:
- Redis内存成本太高
- 80%请求集中在20%数据(二八法则)
- 热点数据动态变化(如突发新闻、秒杀商品)
二、三级缓存治理体系
1. 第一层:智能淘汰策略(守门员)
Redis配置黄金法则:
1 | # redis.conf关键配置maxmemory 20gb # 按20万数据*1KB计算maxmemory-policy allkeys-lfu # 使用LFU算法(Least Frequently Used) |
淘汰策略对比:
| 策略 | 特点 | 适用场景 |
|---|---|---|
allkeys-lfu |
淘汰访问频率最低 | 稳定热点(如商品详情) |
volatile-ttl |
淘汰剩余时间最短 | 限时活动(如秒杀) |
allkeys-random |
随机淘汰 | 无规律访问 |
2. 第二层:实时热点探测(雷达系统)

Flink实时统计代码:
1 | DataStream<ItemViewCount> windowData = data |
3. 第三层:多级缓存架构(防御矩阵)

本地+Redis二级缓存实现:
1 | // Caffeine本地缓存(第一级)LoadingCache<String, Object> localCache = Caffeine.newBuilder() .maximumSize(1000) .expireAfterWrite(30, TimeUnit.SECONDS) .build(key -> { // Redis查询(第二级) Object val = redis.get(key); if(val == null) { val = mysql.get(key); redis.setex(key, 3600, val); // 回填Redis } return val; }); |
三、四大核心优化技巧
1. 热点标记与保护
1 | // 热点标记ConcurrentHashMap<String, AtomicLong> hotKeyCounter = new ConcurrentHashMap<>(); |
2. 冷热数据分离存储
MySQL表优化:
1 | ALTER TABLE products ADD COLUMN hot_score INT DEFAULT 0 COMMENT '热度值', ADD INDEX idx_hot_score (hot_score); |
***Redis存储优化*:
1 | # 使用Hash结构压缩存储HMSET product:1234 data "{...json...}" hot 1 expire 1735689600 |
3. 智能预热机制
1 | # 定时预热脚本(每日凌晨执行)def preheat_cache(): # 获取昨日Top20万热点 hot_items = mysql.query(""" SELECT item_id FROM access_log WHERE date = CURDATE() - INTERVAL 1 DAY GROUP BY item_id ORDER BY COUNT(*) DESC LIMIT 200000 """) |
4. 动态策略调整

四、压测数据对比
| 方案 | 缓存命中率 | 平均延迟 | MySQL负载 |
|---|---|---|---|
| 无缓存 | 0% | 95ms | 100% |
| 基础LRU | 65% | 18ms | 35% |
| 智能方案 | 98.5% | 2.1ms | 1.5% |
五、面试加分项
1.缓存雪崩防护:
-
-
-
1 | // 随机过期时间避免集体失效public void setCache(String key, Object value) { int expire = 3600 + new Random().nextInt(600); // 3600~4200秒随机 redis.setex(key, expire, value);} |
2.热点Key分片:
-
-
1 | def get_cache_key(item_id): shard = item_id % 10 # 分10个片 return f"item_{shard}_{item_id}" |
3.多级降级策略:

六、实战建议
1.每日运维:
- 凌晨低峰期执行缓存分析脚本
- 使用
redis-cli --hotkeys主动探测热点
2.监控预警:
- 对缓存击穿率设置分级报警(>5%触发警告)
- Redis内存使用超过80%时自动扩容
3.业务隔离:
- 不同业务线使用独立缓存实例(如商品、订单分离)
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Calico's Space!
 wechat
wechat


评论




